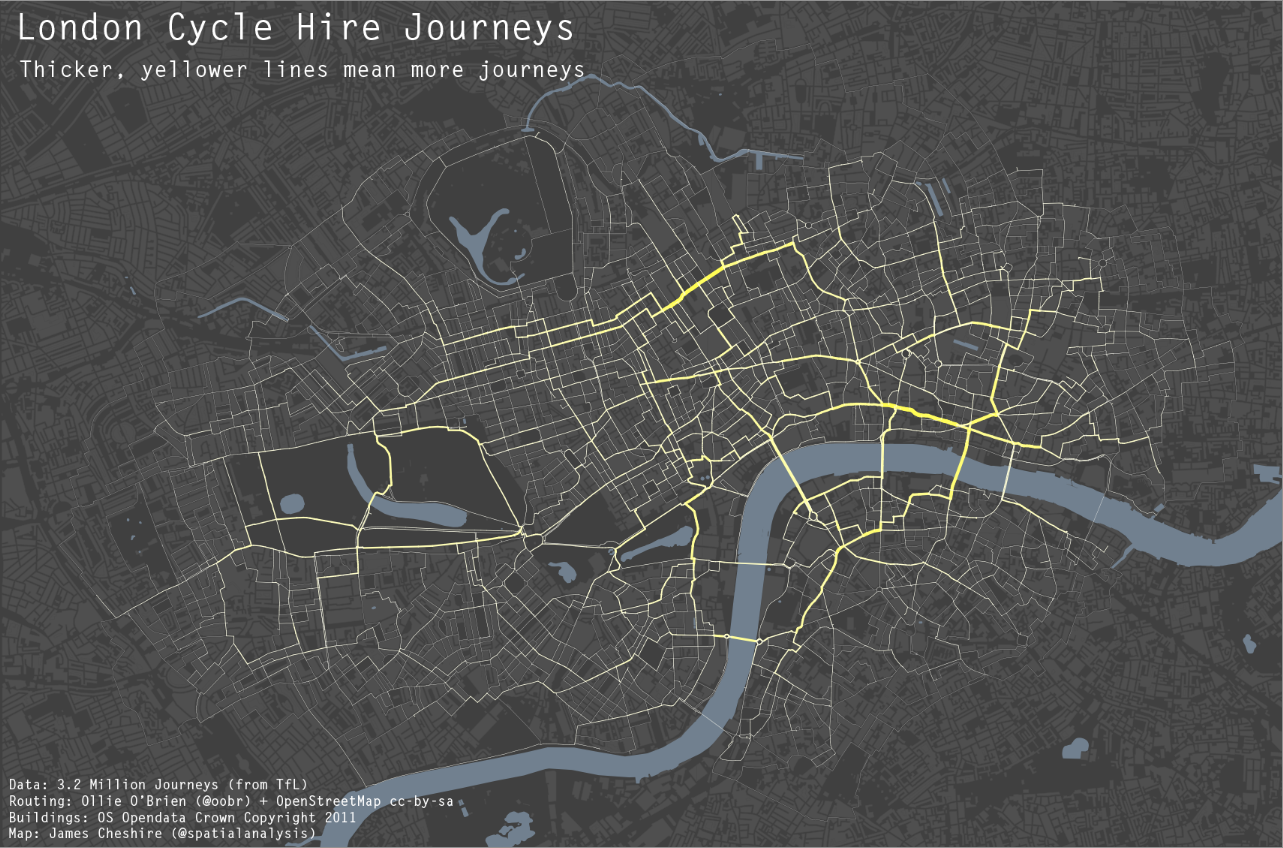
I figured I would write a brief post about my experience blogging. I created this blog and published my first post in December of 2011. Since then, in 2012, I published 30 blog posts, and totaled 7,200 views. While I thought the number was quite high (albeit a bit dissapointing compared to the numbers of Larry Wasserman), it is still many more people than would have listened to what I had to say if I didn’t write a blog. When starting out I averaged under 10 views a day, but throughout the year it steadily grew, and now I average about 30 views per day. The post that had the most traffic in one day was When should we use a black background for a map?, and that was largely because of some twitter traffic (a result of Steven Romalewski tweeting it and then it being re-tweeted by Kenneth Field), and it had 73 views.
I started the blog because I really loved reading alot of others blogs, and so I hope to encourage others to do so as well. It is a nice venue to share work and opinions for an academic, as it is more flexible and can be less formal than articles. Also much of what I write about I would just consider helpful tips or generic discussion that I wouldn’t get to discuss otherwise (SPSS programming and graph tips will never make it into a publication). One of my main motivations was actually R-Bloggers and the SAS blog roll; I would like a similarly active community for SPSS, but there is none really that I have found outside of the NABBLE forum (some exceptions are Andy Field, The Analysis Factor, Jon Peck and these few posts by a Louis K I only found through the labyrinth that is the IBM developerworks site (note I think you need to be signed in to even see that site), but they certainly aren’t very active and/or don’t write much about SPSS). I assume the best way to remedy that is to lead by example! Most of my more popular posts are ones about SPSS, and I frequently get web-traffic via general google searches of SPSS + something else I blogged about (hacking the template and comparing continuous distributions are my two top posts).
Also the blog is also just another place to highlight my academic work and bring more attention to it. WordPress tells me how often someone clicks a link on the blog, and someone has clicked the link to my CV close to 40 times since I’ve made the blog. Hopefully I have some pre-print journal articles to share on the blog in the near future (as well as my prospectus). My post on my presentation at ASC did not generate much traffic, but I would love to see a similar trend for other criminologists/criminal justicians in the future. My work isn’t perfect for sure, but why not get it out there at least for it to be judged and hopefully get feedback.
I would like to blog more, and I actively try to write something if I haven’t in a few weeks, but I don’t stress about it too much. I certainly have an infinite pool of posts to write about programming and generating graphs in SPSS. I have also thought about talking about historical graphics in criminology and criminal justice, or generally talking about some historical and contemporary crime mapping work. Other potential posts I’d like to write about are a more formal treatment about why I loathe most difference-in-differences designs, and perhaps about the sillyness that can ensue when using null-hypothesis significance testing to determine racial bias. But they will both take more careful elaboration on, so might not be anytime soon.
So in short, SPSSer’s, crime mapper’s, criminologist’s/criminal justician’s, I want you to start blogging, and I will eagerly consume your work (and in the meantime hopefully produce some more useful stuff on my end)!











")