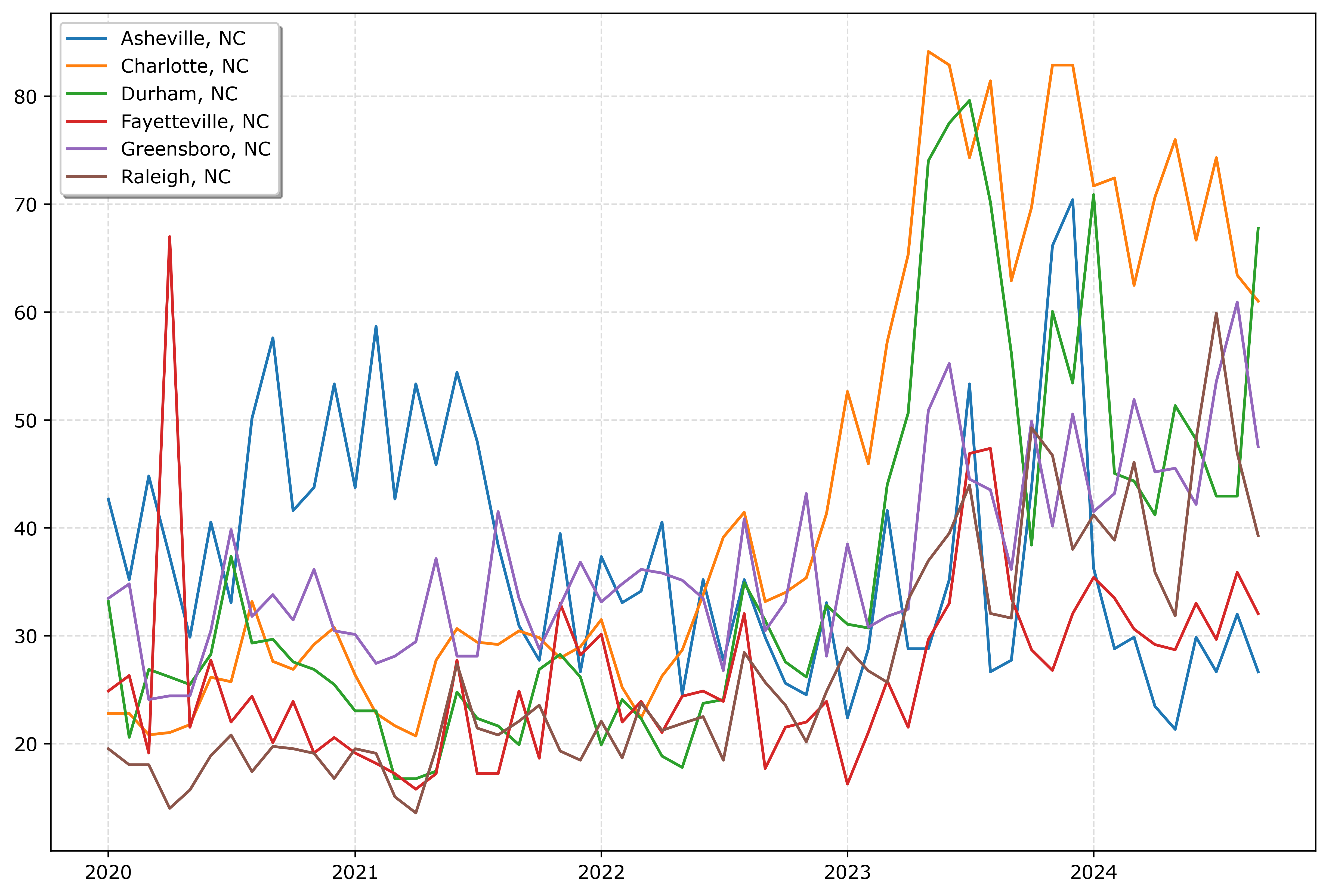
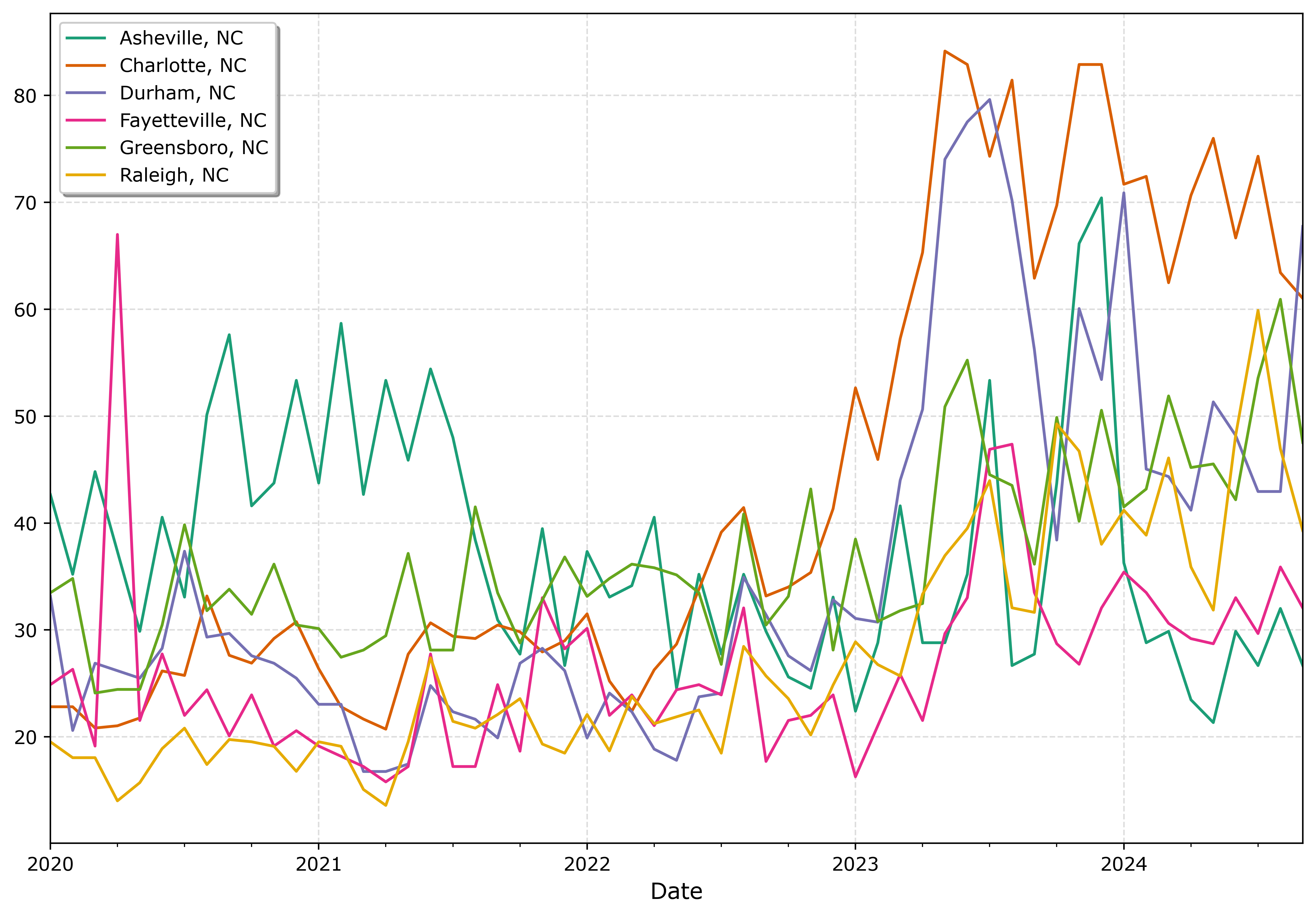
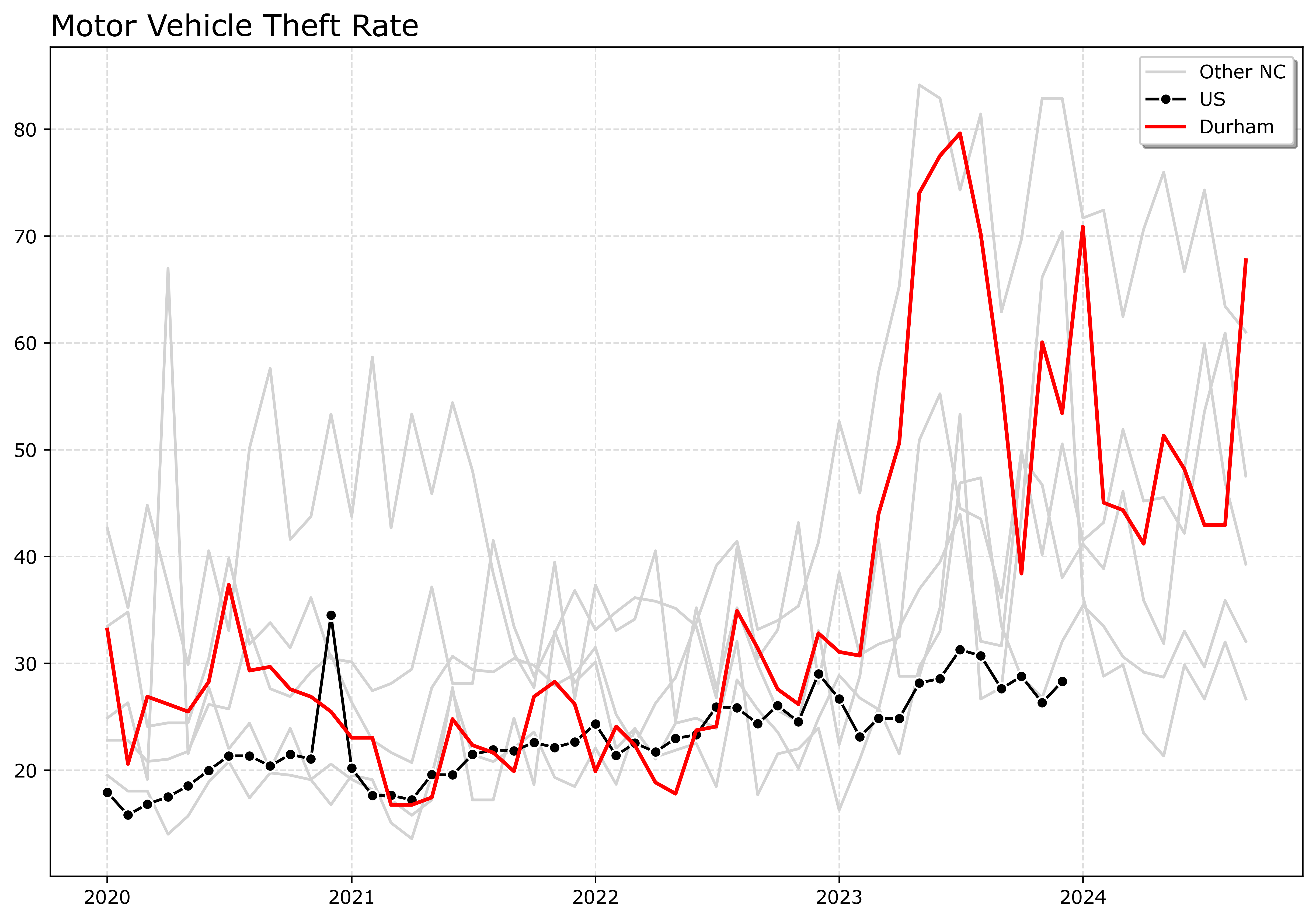
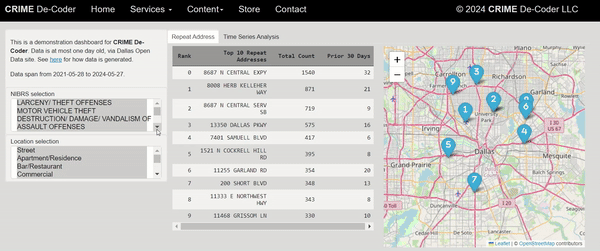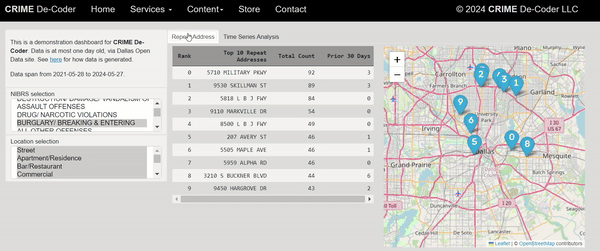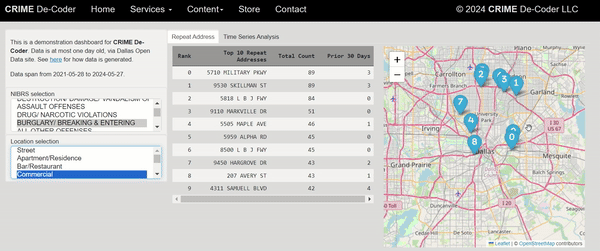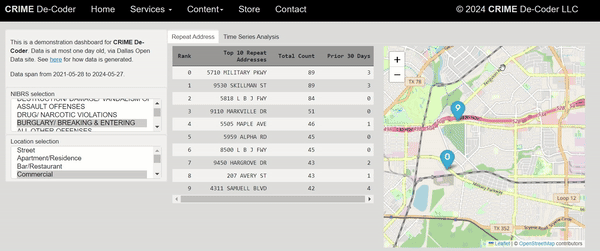
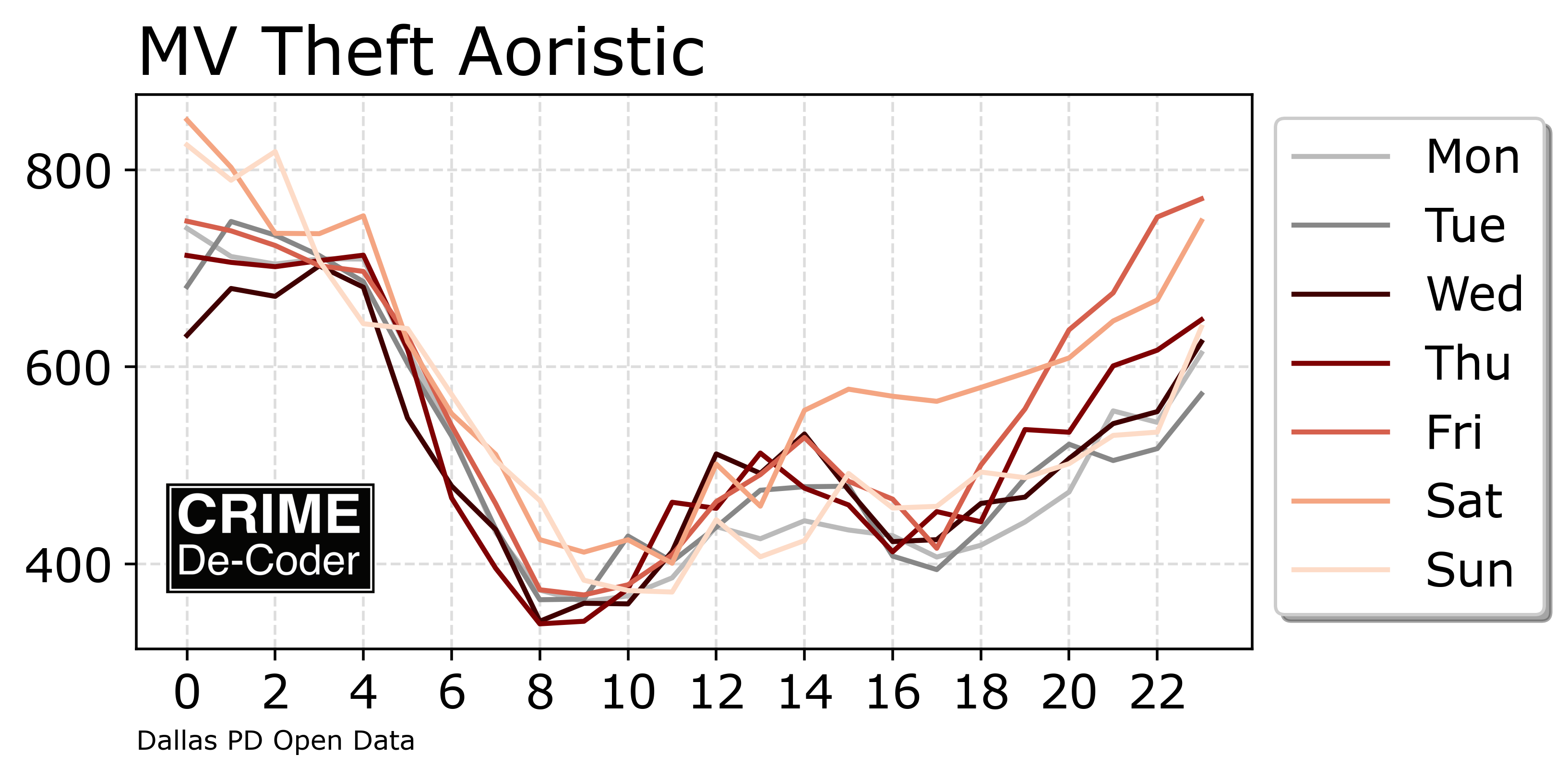
I shared a series of posts this week using Esri + arcpy tools on my Crime De-Coder LinkedIn page. LinkedIn eventually removes the posts though, so I am putting those same tips here on the blog. Esri’s tools do not have great coverage online, so blogging is a way to get more coverage in those LLM tools long term.
A little arcpy tip, if you import a toolbox, it can be somewhat confusing what the names of the methods are available. So for example, if importing some of the tools Chris Delaney has created for law enforcement data management, you can get the original methods available for arcpy, and then see the additional methods after importing the toolbox:
import arcpy
d1 = dir(arcpy) # original methods
arcpy.AddToolbox("C:\LawEnforcementDataManagement.atbx")
d2 = dir(arcpy) # updated methods available after AddToolbox
set(d2) - set(d1) # These are the new methods
# This prints out for me
# {'ConvertTimeField_Defaultatbx', 'toolbox_code', 'TransformCallData_Defaultatbx', 'Defaultatbx', 'TransformCrimeData_Defaultatbx'}
# To call the tool then
arcpy.TransformCrimeData_Defaultatbx(...)Many of the Arc tools have the ability to copy python code, when I use Chris’s tool it copy-pastes arcpy.Defaultatbx.TransformCrimeData, but if running from a standalone script outside of an Esri session (using the python environment that ArcPro installs) that isn’t quite the right code to call the function.
You can check out Chris’s webinar that goes over the law enforcement data management tool, and how it fits into the different crime analysis solutions that Chris and company at Esri have built.
I like using conda for python environments on Window’s machines, as it is easier to install some particular packages. So I mostly use:
conda create --name new_env python=3.11 pip
conda activate new_env
pip install -r requirements.txtBut for some libraries, like geopandas, I will have conda figure out the install. E.g.
conda create --name geo_env python=3.11 pip geopandas
conda activate geo_env
pip install -r requirements.txtAs they are particularly difficult to install with many restrictions.
And if you are using ESRI tools, and you want to install a library, conda is already installed and you can clone that environment.
conda create --clone "C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3" --name proclone
conda activate proclone
pip install -r requirements.txtAs you do not want to modify the original ESRI environment.
Using conda to run scheduled jobs in Windows is alittle tricky. Here is an example of setting up a .bat file (which can be set up in Windows scheduler) to activate conda, set a new conda environment, and call a python script.
::: For log, showing date/time
echo:
echo --------------------------
echo %date% %time%
::: This sets the location of the script, as conda may change it
set "base=%cd%"
::: setting up conda in Windows, example Arc's conda activate
call "C:\Program Files\ArcGIS\Pro\bin\Python\Scripts\activate.bat"
::: activating a new environment
call conda activate proclone
::: running a python script
call cd %base%
call python auto_script.py
echo --------------------------
echo:Then, when I set up the script in Window’s scheduler, I often have the log file at that level. So the task scheduler I will have the action as:
"script.bat" >> log.txt 2>&1And have the options where the script runs from the location of script.bat. This will append both the normal log and error log to the shell script. So if something goes wrong, you can open log.txt and see what is up.
When working with arcpy, often you need to have tables inside of a geodatabase to use particular geoprocessing tools. Here is an example of taking an external csv file, and importing that file into a geodatabase as a table.
import arcpy
gdb = "./project/LEO_Tables.gdb"
tt = "TempTable"
arcpy.env.workspace = gdb
# Convert CSV into geodatabase
arcpy.TableToTable_conversion("YourData.csv",gdb,tt)
#arcpy.ListTables() # should show that new table
# convert time fields into text, useful for law enforcement management tools
time_fields = ['rep_date','begin','end']
for t in time_fields:
new_field = f"{t}2"
arcpy.management.AddField(tt,new_field,"TEXT")
arcpy.management.CalculateField(tt,new_field,f"!{t}!.strftime('%Y/%m/%d %H:%m')", "PYTHON3")
# This will show the new fields
#fn = [f.name for f in arcpy.ListFields(tt)]When you create a new project, it automatically creates a geodatabase file to go along with that project. If you just want a standalone geodatabase though, you can use something like this in your python script:
import arcpy
import os
gdb = "./project/LEO_Tables.gdb"
if os.path.exists(gdb):
pass
else:
loc, db = os.path.split(gdb)
arcpy.management.CreateFileGDB(loc,db)So if the geodatabase does not exist, it creates it. If it does exist though, it will not worry about creating a new one.
One of the examples for automation is taking a basemap, updating some of the elements, and then exporting that map to an image or PDF. This sample code, using Dallas data, shows how to set up a project to do this. And here is the original map:

Because ArgGIS has so many different elements, the arcpy module tends to be quite difficult to navigate. Basically I try to seperate out data processing (which often takes inputs and outputs them into a geodatabase) vs visual things on a map. So to do this project, you have step 1 import data into a geodatabase, and 2 update the map elements. Here legend, title, copying symbology, etc.
You can go to the github project to download all of the data (including the aprx project file, as well as the geodatabase file). But here is the code to review.
import arcpy
import pandas as pd
from arcgis.features import GeoAccessor, GeoSeriesAccessor
import os
# Set environment to a particular project
gdb = "DallasDB.gdb"
ct = "TempCrimes"
ol = "ExampleCrimes"
nc = "New Crimes"
arcpy.env.workspace = gdb
aprx = arcpy.mp.ArcGISProject("DallasExample.aprx")
dallas_map = aprx.listMaps('DallasMap')[0]
temp_layer = f"{gdb}/{ct}"
# Load in data, set as a spatial dataframe
df = pd.read_csv('DallasSample.csv') # for a real project, will prob query your RMS
df = df[['incidentnum','lon','lat']]
sdf = pd.DataFrame.spatial.from_xy(df,'lon','lat', sr=4326)
# Add the feature class to the map, note this does not like missing data
sdf.spatial.to_featureclass(location=temp_layer)
dallas_map.addDataFromPath(os.path.abspath(temp_layer)) # it wants the abs path for this
# Get the layers, copy symbology from old to new
new_layer = dallas_map.listLayers(ct)[0]
old_layer = dallas_map.listLayers(ol)[0]
old_layer.visible = False
new_layer.symbology = old_layer.symbology
new_layer.name = nc
# Add into the legend, moving to top
layout = aprx.listLayouts("DallasLayout")[0]
leg = layout.listElements("LEGEND_ELEMENT")[0]
item_di = {f.name:f for f in leg.items}
leg.moveItem(item_di['Dallas PD Divisions'], item_di[nc], move_position='BEFORE')
# Update title in layout "TitleText"
txt = layout.listElements("TEXT_ELEMENT")
txt_di = {f.name:f for f in txt}
txt_di['TitleText'].text = "New Title"
# If you need to make larger, can do
#txt_di['TitleText'].elementWidth = 2.0
# Export to high res PNG file
layout.exportToPNG("DallasUpdate.png",resolution=500)
# Cleaning up, to delete the file in geodatabase, need to remove from map
dallas_map.removeLayer(new_layer)
arcpy.management.Delete(ct)And here is the updated map: