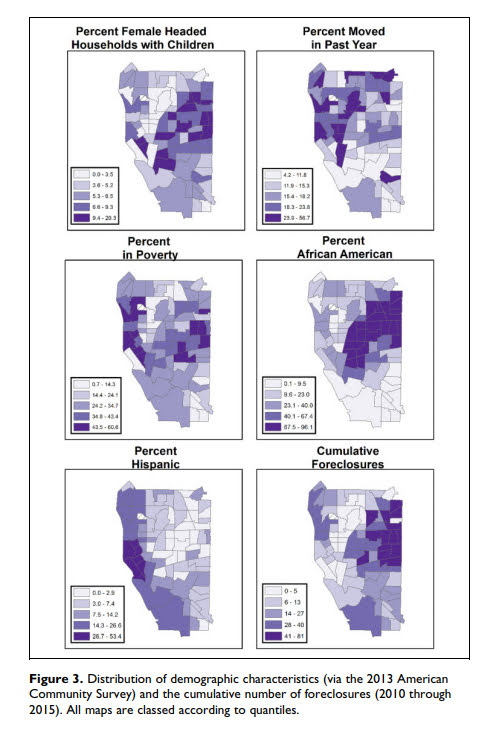
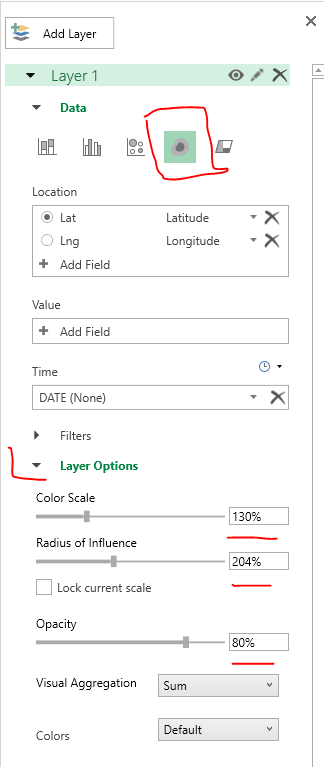
Those interested in micro place based crime analysis often need to collect information on businesses or other facilities where many people gather (e.g. hospitals, schools, libraries, parks). To keep it short, businesses influence the comings-and-goings of people, and those people are those who commit offenses and are victimized. Those doing neighborhood level research census data is almost a one stop shop, but that is not the case when trying to collect businesses data of interest. Here are some tips and resources I have collected over the years of conducting this research.
Alcohol License Data
Most states have a state level board in which one needs to obtain a license to sell alcohol. Bars and liquor stores are one of the most common micro crime generator locations criminologists are interested in, but in most states places like grocery stores, gas stations, and pharmacies also sell alcohol (minus those Quakers in Pennsylvania) and so need a license. So such lists contain many different crime generators of interest. For example here is Texas’s list, which includes a form to search for and download various license data. Here is Washington’s, which just has spreadsheets of the current alcohol and cannabis licenses in the state. To find these you can generally just google something like “Texas alcohol license data”.
In my experience these also have additional fields to further distinguish between the different types of locations. Such as besides the difference between on-premise vs off-premise, you can often also tell the difference between a sit down restaurant vs a more traditional bar. (Often based on the percent of food-stuffs vs alcohol that make up total revenue.) So if you were interested in a dataset of gas stations to examine commercial robbery, I might go here first as opposed to the other sources (again PA is an exception to that advice though, as well as dry counties).
Open Data Websites
Many large cities anymore have open data websites. If you simply google “[Your City] open data” they will often come up. Every city is unique in what data they have available, so you will just have to take a look on the site to see if whatever crime generator you are interested in is available. (These sites almost always contain reported crimes as well, I daresay reported crimes are the most common open data on these websites.) For businesses, the city may have a directory (like Chicago). (That is not the norm though.) They often have other points/places of interest as well, such as parks, hospitals and schools.
Another example is googling “[your city] GIS data”. Often cities/counties have a GIS department, and I’ve found that many publicly release some data, such as parcels, zoning, streets, school districts, etc. that are not included on the open data website. For example here is the Dallas GIS page, which includes streets, parcels, and parks. (Another pro-tip is that many cities have an ArcGIS data server lurking in the background, often which you can use to geocode address data. See these blog posts of mine (python,R) for examples. ) If you have a county website and you need some data, it never hurts to send a quick email to see if some of those datasets are available (ditto for crime via the local crime analyst). You have nothing to lose by sending a quick email to ask.
I’d note that sometimes you can figure out a bit from the zoning/parcel dataset. For instance there may be a particular special code for public schools or apartment complexes. NYC’s PLUTO data is the most extensive I have ever seen for a parcel dataset. Most though have simpler codes, but you can still at least figure out apartments vs residential vs commercial vs mixed zoning.
You will notice that finding these sites involve using google effectively. Since every place is idiosyncratic it is hard to give general advice. But google searches are easy. Recently I needed public high schools in Dallas for a project, and it was not on any of the prior sources I noted. A google search however turned up a statewide database of the public and charter school locations. If you include things like “GIS” or “shapefile” or “data” in the search it helps whittle it down some to provide a source that can actually be downloaded/manipulated.
Scraping from public websites
The prior two sources are generally going to be better vetted. They of course will have errors, but are typically based on direct data sources maintained by either the state or local government. All of the other sources I will list though are secondary, and I can’t really say to what extent they are incorrect. The biggest thing I have noticed with these data sources is that they tend to be missing facilities in my ad-hoc checks. (Prior mentioned sources at worst I’ve noticed a rare address swap with a PO box that was incorrect.)
I’ve written previously about using the google places API to scrape data. I’ve updated to create a short python code snippet that all you need is a bounding box you are looking for and it will do a grid search over the area for the place type you are interested in. Joel Caplan has a post about using Google Earth in a similar nature, but unfortunately that has a quite severe limitation — it only returns 10 locations. My python code snippet has no such limitation.
I don’t really understand googles current pricing scheme, but the places API has a very large number of free requests. So I’m pretty sure you won’t run out even when scraping a large city. (Geocoding and distance APIs are much fewer unfortunately, and so are much more limited.)
Other sources I have heard people use before are Yelp and Yellow pages. I haven’t checked those sources extensively (and if they have API’s like Google). When looking closely at the Google data, it tends to be missing places (it is up to the business owner to sign up for a business listing). Despite it being free and seemingly madness to not take the step to have your business listed easily in map searches, it is easy to find businesses that do not come up. So user beware.
Also, scraping the data for academic articles is pretty murky whether it violates the terms of service for these sites. They say you can’t cache the original data, but if you just store the lat/lon and then turn into a “count of locations” or a “distance to nearest location” (ala risk terrain modelling), I believe that does not violate the TOS (not a lawyer though — so take with a grain of salt). Also for academic projects since you are not making money I would not worry too extensively about being sued, but it is not a totally crazy concern.
Finally, the nature of scraping the business data is no different than other researchers who have been criticized for scraping public sites like Facebook or dating websites (it is just a business instead of personal info). I personally don’t find it unethical (and I did not think those prior researchers were unethical), but others will surely disagree.
City Observatory Data
City observatory has a convenient set of data, that they named the StoreFront Index. They have individual data points you can download for many different metro areas, along with their SIC codes. See also here for a nice map and to see if your metro area of interest is included.
See here for the tech report on which stores are included. They do not include liquor stores and gas stations though in their index. (Since it is based on Jane Jacob’s work I presume they also do not include used car sale lots.)
Lexis Nexis Business Data (and other proprietary sources)
The store front data come from a private database, Custom Lists U.S. Business Database. I’m not sure exactly what vendor produces this (a google search brings up several), but here are a few additional proprietary sources researchers may be interested in.
My local library in Plano (as well as my University), have access to a database named reference USA. This allows you to search for businesses in a particular geo area (such as zip code), as well as by other characteristics (such as by the previously mentioned SIC code). Also this database includes additional info. about sales and number of employees, which may be of further interest to tell the difference between small and large stores. (Obviously Wal-Mart has more customers and more crime than a smaller department store.) It provides the street address, which you will then need to geocode.
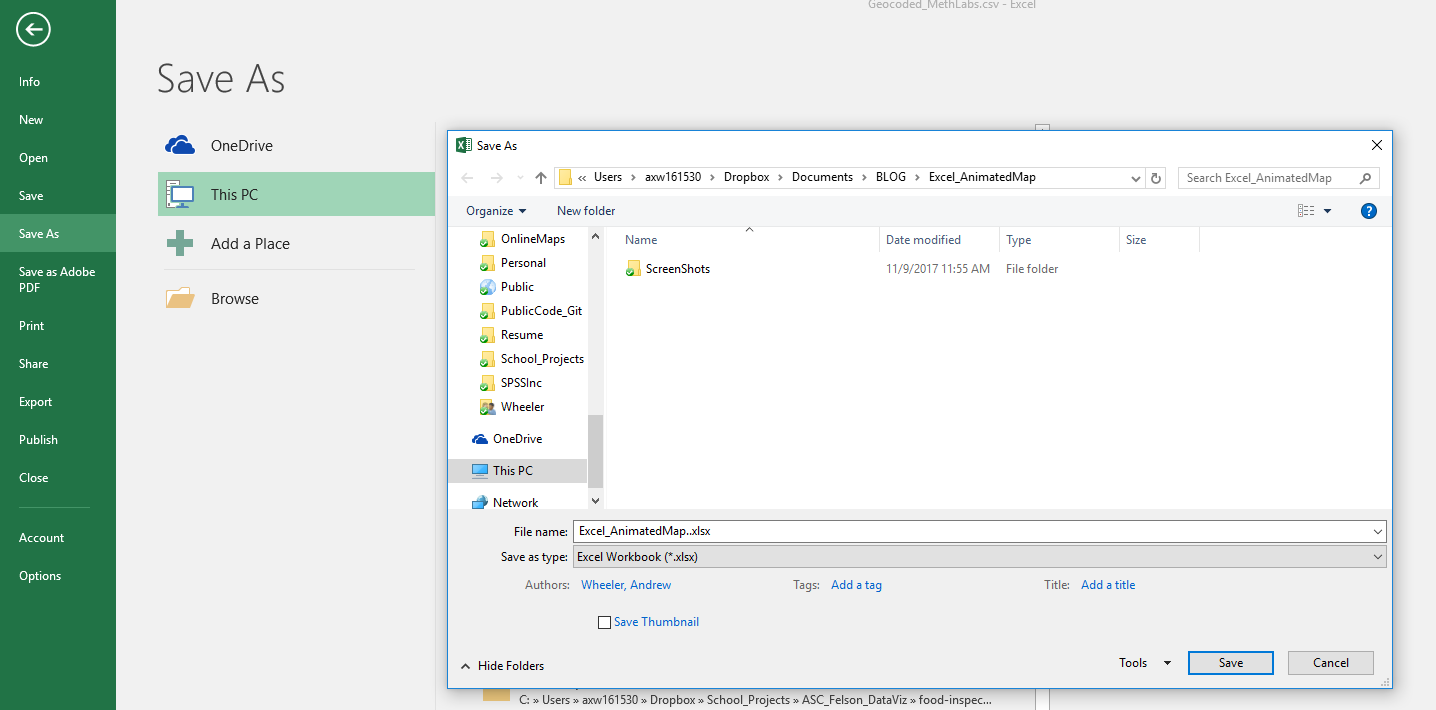
Reference USA though only allows you to download 250 addresses at a time, so could be painful for crime generators that are more prevalent or for larger cities. Another source though my friendly UTD librarian pointed out to me is Lexis Nexis’s database of public businesses. It has all the same info. as reference USA and you can bulk download the files. See here for a screenshot walkthrough my librarian created for me.
Any good sources I am missing? Let me know in the comments. In particular these databases I mention are cross-sectional snapshots in time. It would be difficult to use these to measure changes over time with few exceptions.