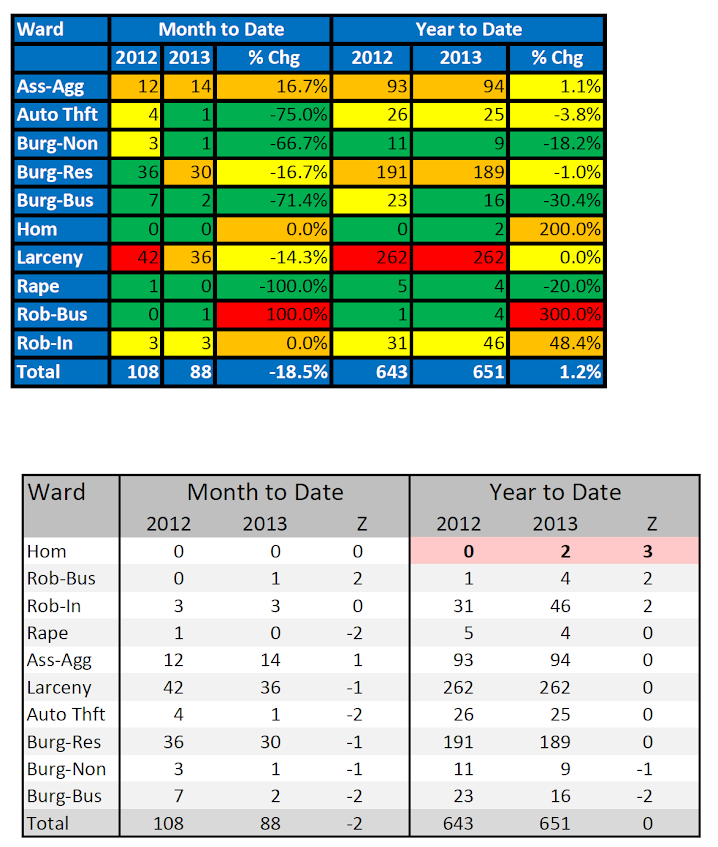
An interesting debate/question came up in my work recently. I conducted an analysis of a violence risk assessment tool for a police department. Currently the PD takes around the top 1,000 scores of this tool, and then uses further intelligence and clinical judgements to place a small number of people on a chronic offender list (who are then subject to further interventions). My assessment of the predictive validity when examining ROC curves suggested the tool does a pretty good job discriminating violent people up to around the top 6,000 individuals and after that flattens out. In a sample of over 200,000, the top 1000 scores correctly classified 30 of the 100 violent cases, and the top 6000 classified 60.
So the question came up should we recommend that the analysts widen the net to the top 6,000 scores, instead of only examining the top 1,000 scores? There are of course costs and limitations of what the analysts can do. It may simply be infeasible for the analysts to review 6,000 people. But how do you set the limit? Should the clinical assessments be focused on even fewer individuals than 1,000?
We can make some estimates of where the line should be drawn by setting weights for the cost of a false positive versus a false negative. Implicit in the whole exercise of predicting violence in a small set of people is that false negatives (failing to predict someone will be violent when they are) greatly outweigh a false positive (predicting someone will be violent but they are not). The nature of the task dictates that you will always need to have quite a few false positives to classify even a few true positives, and no matter what you do there will only be a small number of false negatives.
Abstractly, you can place a value on the cost of failing to predict violence, and a cost on the analysts time to evaluate cases. In this situation we want to know whether the costs of widening the net to 6,000 individuals are less than the costs of only examining the top 1,000 individuals. Here I will show we don’t even need to know what the exact cost of a false positive or a false negative is, only the relative costs, to make an estimate about whether the net should be cast wider.
The set up is that if we only take the top 1,000 scores, it will capture 30 out of the 100 violent cases. So there will be (100 – 30) false negatives, and (1000 – 30) false positives. If we increase the scores to evaluate the top 6,000, it will capture 60 out the 100 violent cases, but then we will have (6000 – 60) false positives. I can not assign a specific number to the cost of a false negative and a false positive. So we can write these cost equations as:
1) (100 - 30)*FN + (1000 - 30)*FP = Cost Low
2) (100 - 60)*FN + (6000 - 60)*FP = Cost HighEven though we do not know the exact cost of a false negative, we can talk about relative costs, e.g. 1 false negative = 1000*false positives. There are too many unknowns here, so I am going to set FP = 1. This makes the numbers relative, not absolute. So with this constraint the reduced equations can be written as:
1) 70*FN + 970 = Cost Low
2) 40*FN + 5940 = Cost HighSo we want to know the ratio at which there is a net benefit over including the top 6,000 scores versus only the top 1,000. So this means that Cost High < Cost Low. To figure out this point, we can subtract equation 2 from equation 1:
3) (70 - 40)*FN - 4970 = Cost Low - Cost HighIf we set this equation to zero and solve for FN we can find the point where these two equations are equal:
30*FN - 4970 = 0
30*FN = 4970
FN = 4970/30 = 165 + 2/3If the value of a false negative is more than 166 times the value of a false positive, Cost Low - Cost High will be positive, and so the false negatives are more costly to society relative to the analysts time spent. It is still hard to make guesses as to whether the cost of violence to society is 166 times more costly than the analysts time, but that is at least one number to wrap your head around. In a more concrete example, such as granting parole or continuing to be incarcerated, given how expensive prison is net widening (with these example numbers) would probably not be worth it. But here it is a bit more fuzzy especially because the analysts time is relatively inexpensive. (You also have to guess how well you can intervene, in the prison example incarceration essentially reduces the probability of committing violence to zero, whereas police interventions can not hope to be that successful.)
As long as you assume that the classification rate is linear within this range of scores, the same argument holds for net widening any number. But in reality there are diminishing returns the more scores you examine (and 6,000 is basically where the returns are near zero). If you conduct the same exercise between classifying zero and the top 1,000, the rate of the cost of a false negative to a false positive needs be 32+1/3 to justify evaluating the top 1,000 scores. If you actually had an estimate of the ratio of the cost of false positives to false negatives you could then figure out exactly how wide to make the net. But if you think the ratio is well above 166, you have plenty of reason to widen the net to the larger value.