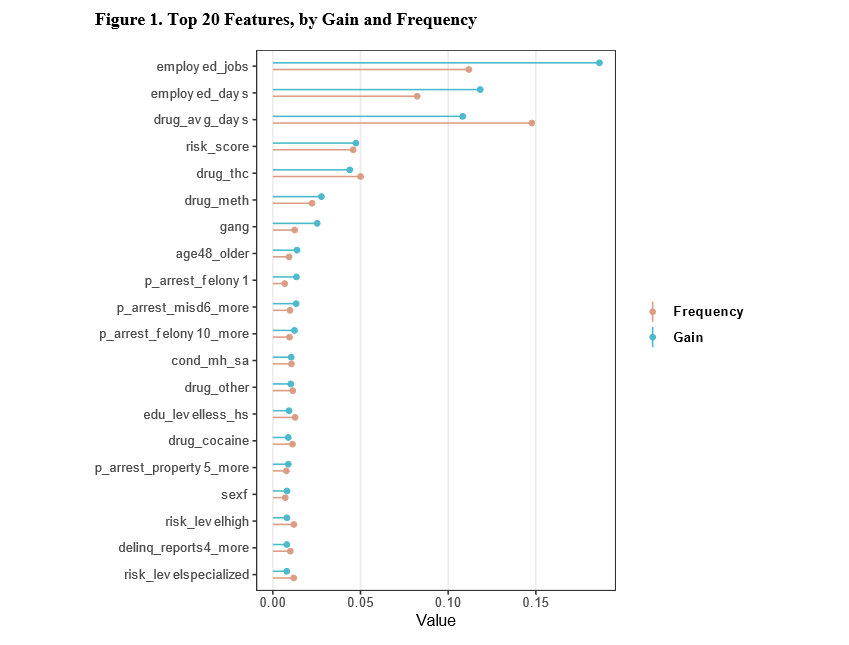
I had a question the other day on my TURF analysis about generating not just the single best solution for a linear programming problem, but multiple solutions. This is one arena I like the way people typically do genetic algorithms, in that they have a leaderboard with multiple top solutions. Which is nice for exploratory data analysis.
This example though it is pretty easy to amend the linear program to return exact solutions by generating lazy constraints. (And because the program is fast, you might as well do it this way as well to get an exact answer.) The way it works here, we have decision variables for products selected. You run the linear program, and then collect the k products selected, then add a constraint to the model in the form of:
Sum(Product_k) <= k-1 Then rerun the model with this constraint, get the solution, and then repeat. This constraint makes it so the group of decision variables selected cannot be replicated (and in the forbidden set). Python’s pulp makes this quite easy, and here is a function to estimate the TURF model I showed in that prior blog post, but generate this multiple leaderboard:
import pandas as pd
import pulp
# Function to get solution from turf model
def get_solution(prod_dec,prod_ind):
'''
prod_dec - decision variables for products
prod_ind - indices for products
'''
picked = []
for j in prod_ind:
if prod_dec[j].varValue >= 0.99:
picked.append(j)
return picked
# Larger function to set up turf model
# And generate multiple solutions
def turf(data,k,solutions):
'''
data - dataframe with 0/1 selected items
k - integer for products selected
solutions - integer for number of potential solutions to return
'''
# Indices for Dec variables
Cust = data.index
Prod = list(data)
# Problem and Decision Variables
P = pulp.LpProblem("TURF", pulp.LpMaximize)
Cu = pulp.LpVariable.dicts("Customers Reached", [i for i in Cust], lowBound=0, upBound=1, cat=pulp.LpInteger)
Pr = pulp.LpVariable.dicts("Products Selected", [j for j in Prod], lowBound=0, upBound=1, cat=pulp.LpInteger)
# Objective Function (assumes weight = 1 for all rows)
P += pulp.lpSum(Cu[i] for i in Cust)
# Reached Constraint
for i in Cust:
#Get the products selected
p_sel = data.loc[i] == 1
sel_prod = list(p_sel.index[p_sel])
#Set the constraint
P += Cu[i] <= pulp.lpSum(Pr[j] for j in sel_prod)
# Total number of products selected constraint
P += pulp.lpSum(Pr[j] for j in Prod) == k
# Solve the equation multiple times, add constraints
res = []
km1 = k - 1
for _ in range(solutions):
P.solve()
pi = get_solution(Pr,Prod)
# Lazy constraint
P += pulp.lpSum(Pr[j] for j in pi) <= km1
# Add in objective
pi.append(pulp.value(P.objective))
res.append(pi)
# Turn results into nice dataframe
cols = ['Prod' + str(i+1) for i in range(k)]
res_df = pd.DataFrame(res, columns=cols+['Reach'])
res_df['Reach'] = res_df['Reach'].astype(int)
return res_dfAnd now we can simply read in our data, turn it into binary 0/1, and then generate the multiple solutions.
#This is simulated data from XLStat
#https://help.xlstat.com/s/article/turf-analysis-in-excel-tutorial?language=en_US
prod_data = pd.read_csv('demoTURF.csv',index_col=0)
#Replacing the likert scale data with 0/1
prod_bin = 1*(prod_data > 3)
# Get Top 10 solutions
top10 = turf(data=prod_bin,k=5,solutions=10)
print(top10)Which generates the results:
>>> print(top10)
Prod1 Prod2 Prod3 Prod4 Prod5 Reach
0 Product 4 Product 10 Product 15 Product 21 Product 25 129
1 Product 3 Product 15 Product 16 Product 25 Product 26 129
2 Product 4 Product 14 Product 15 Product 16 Product 26 129
3 Product 14 Product 15 Product 16 Product 23 Product 26 129
4 Product 3 Product 15 Product 21 Product 25 Product 26 129
5 Product 10 Product 15 Product 21 Product 23 Product 25 129
6 Product 4 Product 10 Product 15 Product 16 Product 27 129
7 Product 10 Product 15 Product 16 Product 23 Product 27 129
8 Product 3 Product 10 Product 15 Product 21 Product 25 128
9 Product 4 Product 10 Product 15 Product 21 Product 27 128I haven’t checked too closely, but this looks to me offhand like the same top 8 solutions (with a reach of 129) as the XLStat website. The last two rows are different, likely because there are further ties.
For TURF analysis, you may actually consider a lazy constraint in the form of:
Product_k = 0 for each kThis is more restrictive, but if you have a very large pool of products, will ensure that each set of products selected are entirely different (so a unique set of 5 products for every row). Or you may consider a constraint in terms of customers reached instead of on products, so if solution 1 reaches 129, you filter those rows out and only count newly reached people in subsequent solutions. This ensures each row of the leaderboard above reaches different people than the prior rows.