
One of the most vexing aspects of spatial analysis in the social sciences in the concept of neighborhoods. There is a large literature on neighborhood effects in criminology, but no one can really define a neighborhood. For analysis they are most often assumed to approximately conform to census areas (like tracts or blocks). Sometimes there are obvious physical features that divide neighborhoods (most often a major roadway), but more often boundaries are fuzzy.
I’ve worked on several surveys (at the Finn Institute) in which we ask people what neighborhood they live in as well as the nearest intersection to their home. Even where there is a clear border, often people say the “wrong” neighborhood, especially near the borders. IIRC, when I calculated the wrongness for one survey in Syracuse we did it was only around 60% of the time the respondents stated they lived the right neighborhood. I do scare quotes around “wrong” because it is obviously arbitrary where people draw the boundaries, so more people saying the wrong neighborhood is indicative of the borders being misaligned than the respondents being wrong.
For this reason I like the Google maps approach in which they just place a label at the approximate center of noteworthy neighborhoods. I emulated this for a recent background map I made for a paper in Albany. (Maps can be opened in a separate tab to see a larger image.)
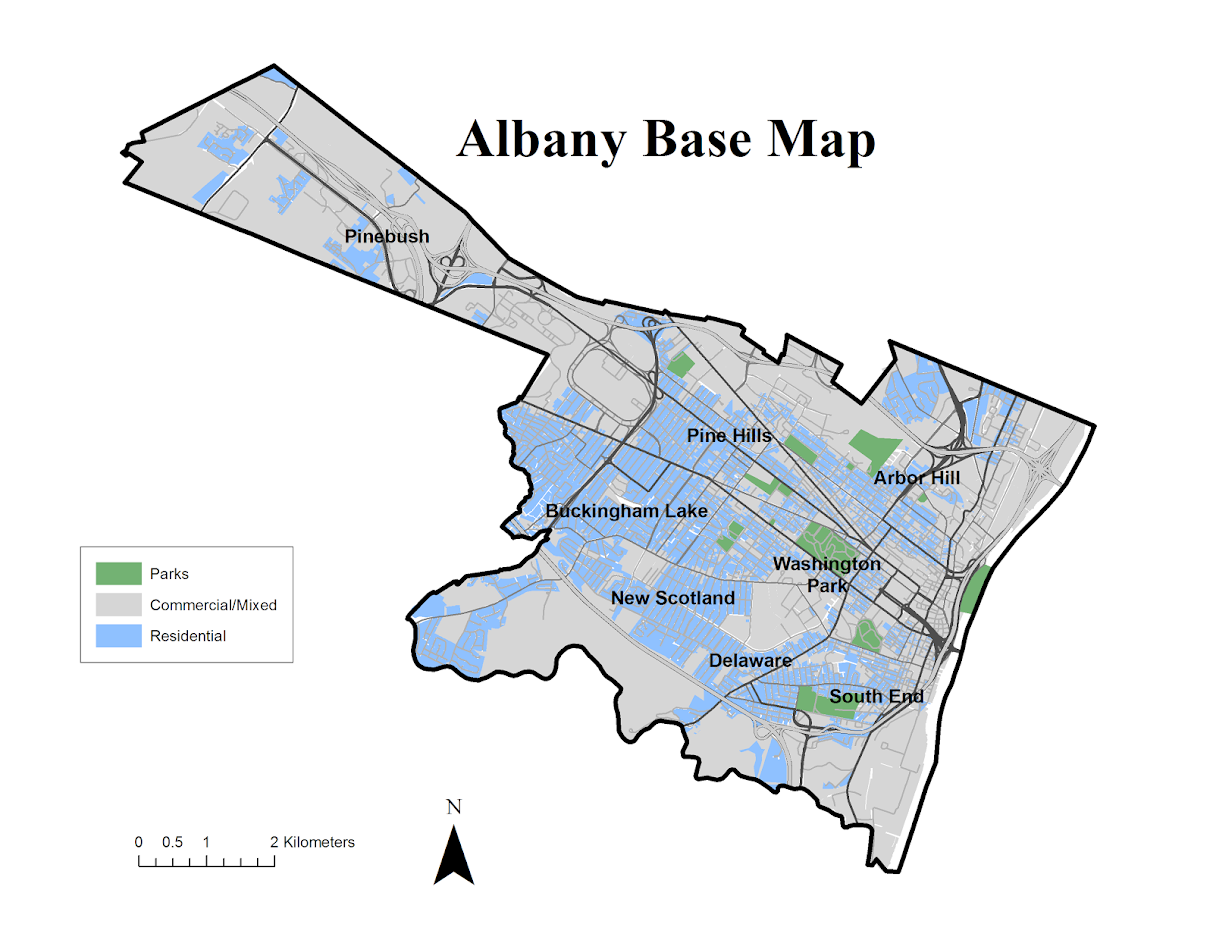
As background I did not grow up in Albany, but I’ve lived and worked in the Capital District since I came up to Albany for grad school – since 2008. Considering this and the fact that I make maps of Albany on a regular basis is my defense I have a reasonable background to make such judgements.
When looking at Google’s reverse geocoding API the other day I noticed they returned a neighborhood field in the response. So I created a regular sampling grid over Albany to see what they return. First, lets see my grid and where Google actually decides some neighborhood exists. Large grey circles are null, and small red circles some neighborhood label was returned. I have no idea where Google culls such neighborhood labels from.
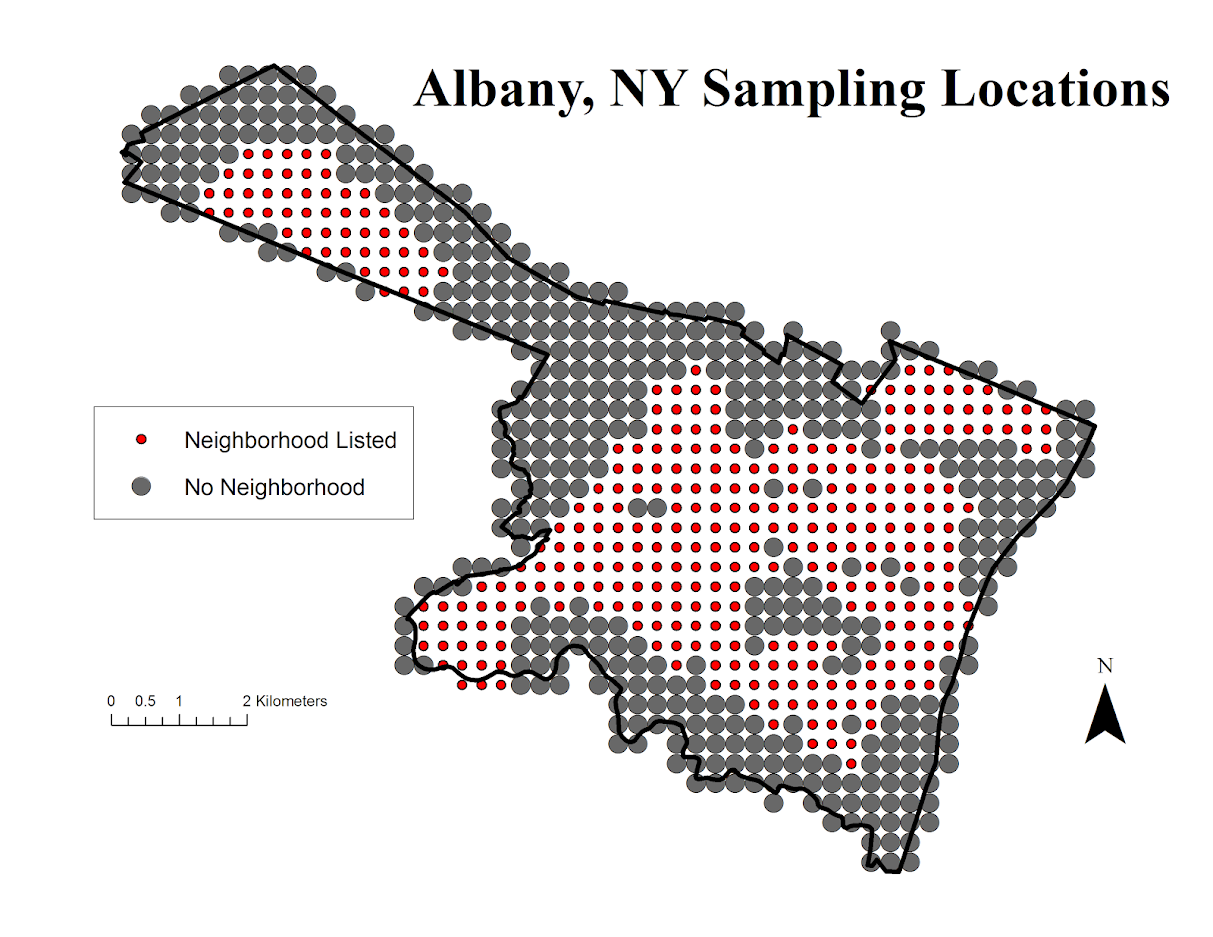
See my python code at the end of the post to see how I extracted this info. given an input lat-lng. In the reverse geo api they return multiple addresses – but I only examine the first returned address and look for a neighborhood. (So I could have missed some neighborhoods this way – it would take more investigation.)
Given the input fishnet I then dissolved the neighborhood labels into areas. Google has quite a few more specific neighborhoods than me.
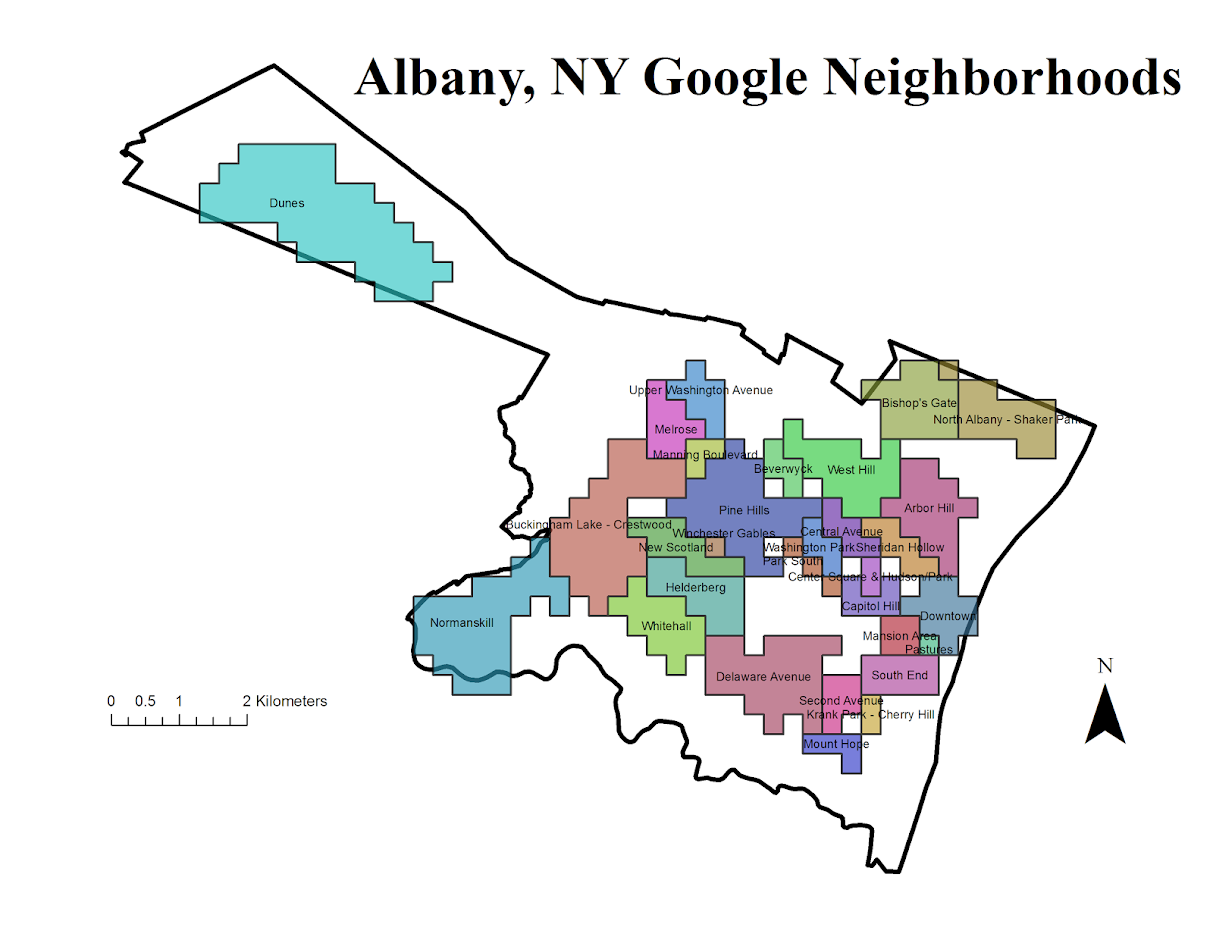
I’ve never really made much of a distinction between West Hill and Arbor Hill – although the split is clearly at Henry Johnson. Also I tend to view Pine Hill as the triangle between Western and Central before the State campus – but Google and others seem to disagree with me. What I call the Pinebush Google calls the Dunes. Dunes is appropriate, because it actually has sand dunes, but I can’t recall anyone referring to it as that. Trees are pretty hard to come by in Arbor Hill though, so don’t be misled. Also kill is Dutch for creek, so you don’t have to worry that Normanskill is such a bad place (even if your name is Norman).
For a third opinion, see albany.com
You can see more clearly in this map how Pine Hill’s area goes south of Madison. Google maps has a fun feature showing related maps, and so they show a related map on someones take for where law students should or should not get an apartment. In that map you can see that south of Madison is affectionately referred to as the student ghetto. That comports with my opinion as well, although I did not think putting student ghetto was appropriate for my basemap for a journal article!
People can’t seem to help but shade Arbor Hill in red. Which sometimes may be innocent – if red is the first color used in defaults (as Arbor Hill will be the first neighborhood in an alphabetic list). But presumably the law student making the apartment suggestions map should know better.
In short, it would be convenient for me (as a researcher) if everyone could agree with what a neighborhood is and where its borders are, but that is not reality.
Here is the function in Python to grab the neighborhood via the google reverse geocoding API. Here if it returns anything it grabs the first address returned and searches for the neighborhood in the json. If it does not find a neighborhood it returns None.
#Reverse geocoding and looking up neighborhoods
import urllib, json
def GoogRevGeo(lat,lng,api=""):
base = r"https://maps.googleapis.com/maps/api/geocode/json?"
GeoUrl = base + "latlng=" + str(lat) + "," + str(lng) + "&key=" + api
response = urllib.urlopen(GeoUrl)
jsonRaw = response.read()
jsonData = json.loads(jsonRaw)
neigh = None
if jsonData['status'] == 'OK':
for i in jsonData['results'][0]['address_components']:
if i['types'][0] == 'neighborhood':
neigh = i['long_name']
break
return neigh












{kind=link}