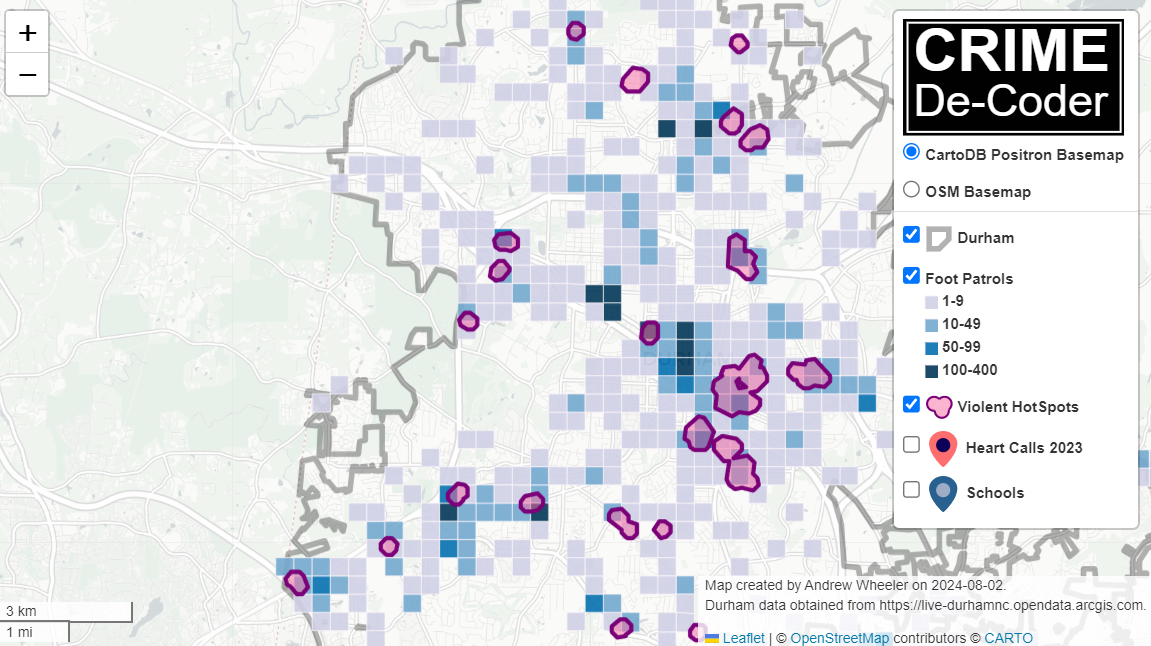
I had a friend the other day interested in a hypothesis along the lines of “I think the mix of crime at a location is different”, in particular they think it will be pushed to more lower level property (and fewer violent) based on some local characteristics. I had a few ideas on this – Brantingham (2016) and Lentz (2018) have examples of creating a permutation type test. And I think I could build a regression multinomial type model (similar to Wheeler et al. 2018) to generate a surface of crime category prediction types over a geographic area (e.g. area A has a mix of 50% property and 50% violent, and area B has a mix of 10% violent and 90% property).
Another approach though is pure machine learning and using conformal sets. I have always been confused about them (see my comment on Gelman’s blog) – reading some more about conformal sets though my comments on Andrew Gelman’s post are mostly confused but partly right. In short you can set recall on a particular class using conformal sets, but you cannot set precision (or equivalently set the false positive rate). So here are my notes on that.
For a CJ application of conformal sets, check out Kuchibhotla & Berk (2023). The idea is that you are predicting categorical classes, in the Berk paper it is recidivism classification with three categories {violent,non-violent,no recidivism}. Say we had a prediction for an individual for the three categories as {0.1,0.5,0.4} – you may say that this person has the highest predicted category of non-violent. Conformal sets are different, in that they can return multiple categories based on a decision threshold, e.g. predict {non-violent,no-recidivism} in this example.
My comment on Gelman’s blog is confused, in that I always thought “why not just take the probabilities to get the conformal set”, so if I wanted a conformal set of 90%, the non-violent and no recidivism probabilities add up to 90%, so wouldn’t they count? But that is not what conformal sets give you, conformal sets only make sense in the repeated frequentist sense I do this thing over and over again, what happens. So with conformal sets so you get Prob(Predict > Threshold | True ) = 0.95, or whatever conformal proportion you want. (I like to call this “coverage”, so out of those True outcomes, what threshold will cover 95% of them.)
This blog post with the code examples really helped my understanding, and how conformal sets can be applied to individual categories (which I think makes more sense than the return multiple labels scenario).
I have code to replicate on github, using data from the NIJ recidivism competition (Circo & Wheeler, 2022) as an example. See some of my prior posts for the feature engineering example, but I use the out of bag trick for random forests in lieu of having a separate calibration sample.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# NIJ Recidivism data with some feature engineering
pdata = pd.read_csv('NIJRecid.csv') # NIJ recidivism data
# Train/test split and fit model
train = pdata[pdata['Training_Sample'] == 1]
test = pdata[pdata['Training_Sample'] == 0]
yvar = 'Recidivism_Arrest_Year1'
xvar = list(pdata)[2:]
# Random forest, need to set OOB to true
# for conformal (otherwise need to use a seperate calibration sample)
rf = RandomForestClassifier(max_depth=5,min_samples_leaf=100,random_state=10,n_estimators=1000,oob_score=True)
rf.fit(train[xvar],train[yvar])
# Out of bag predictions
probs = rf.oob_decision_function_
Now I have intentionally made this as simple as possible (the towards data science post has a small sample quantile correction, plus has a habit of going back and forth between P(y=1) and 1 - P(y=1)). But to get a conformal threshold in this scenario to set the recall at 95% is quite simple:
# conditional predictions for actual 1's
p1 = probs[train[yvar]==1,1]
# recall 95% coverage
k = 95
cover95 = np.percentile(p1,100-k)
print(f'Threshold to have conformal set of {k}% for capturing recidivism')
print(f'{cover95:,.3f}')
# Now can check out of sample
ptest = rf.predict_proba(test[xvar])
out_cover = (ptest[test[yvar]==1,1] > cover95).mean()
print(f'\nOut of sample coverage at {k}%')
print(f'{out_cover:,.3f}')
And this results in for this data:

So this is again recall, or I like to call it the capture rate of the true positives. It is true_positives / (true_positives + false_negatives). This threshold value is estimated purely based on the calibration sample (or here the OOB estimates). The model I will show is not very good, but the conformal sets you still get good performance. So this is quite helpful, having a good estimator (based on exchangeability, so no drift over time). I think in practice though that will not be bad (I by default auto-retrain models I put into production on a regular schedule, e.g. retrain once a month), so I don’t bother monitoring drift.
You can technically do this for each class, so you can have a recall set for the true negatives as well:
# can also set the false negative rate in much the same way
p0 = probs[train[yvar]==0,0]
# false negative rate set to 5%
k = 95
cover95 = np.percentile(p0,100-k)
print(f'Threshold (for 0 class) to have conformal set of {k}% for low risk')
print(f'{cover95:,.3f}')
# Now can check out of sample
out_cover = (ptest[test[yvar]==0,0] > cover95).mean()
print(f'\nOut of sample coverage at {k}%')
print(f'{out_cover:,.3f}')
Note that the threshold here is for P(y=0),
Threshold (for 0 class) to have conformal set of 95% for low risk
0.566
Out of sample coverage at 95%
0.953
Going back to the return multiple labels idea, in this example for predictions (for the positive class) we would have this breakdown (where 1 – 0.566 = 0.434):
P < 0.19 = {no recidivism}
0.19 < P < 0.434 = {no recidivism,recidivism}
0.434 < P = {recidivism}
Which I don’t think is helpful offhand, but it would not be crazy for someone to want to set the recall (for either class on its own) as a requirement in practice. So say we have a model that predicts some very high risk event (say whether to open an investigation into potential domestic terrorist activity). We may want the recall for the positive class to be very high, so even if it is a lot of nothing burgers, we have some FBI agent at least give some investigation into the predicted individuals.
For the opposite scenario, say we are doing release on recognizance for pre-trial in lieu of bail. We want to say, of those who would not go onto recidivate, we only want to “falsely hold pretrial” 5%, so this is a 95% conformal set of True Negative/(True Negative + False Positive) = 0.95. This is what you get in the second example above for no-recidivism.
Note that this is not the false positive rate, which is False Positive/(True Positive + False Positive), which as far as I can tell you cannot determine via conformal sets. If I draw my contingency table (use fp as false positive, tn as true negative, etc.) Conformal sets condition on the columns, whereas the false positive rate conditions on the second row.
True
0 1
-----------
Pred 0 | tn | fn |
------------
1 | fp | tp |
------------
So what if you want to set the false positive rate? In batch I know how to set the false positive rate, but this random forest model happens to not be very well calibrated:
# This models calibration is not very good, it is overfit
dfp = pd.DataFrame(probs,columns=['Pred0','Pred1'],index=train.index)
dfp['y'] = train[yvar]
dfp['bins'] = pd.qcut(dfp['Pred1'],10)
dfp.groupby('bins')[['y','Pred1']].sum()

So I go for a more reliable logistic model, which does result in more calibrated predictions in this example:
# So lets do a logit model to try to set the false positive rate
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_curve
# Making a second calibration set
train1, cal1 = train_test_split(train,train_size=10000)
logitm = LogisticRegression(random_state=10,penalty=None,max_iter=100000)
logitm.fit(train1[xvar],train1[yvar])
probsl = logitm.predict_proba(cal1[xvar])
# Can see here that the calibration is much better
dflp = pd.DataFrame(probsl,columns=['Pred0','Pred1'],index=cal1.index)
dflp['y'] = cal1[yvar]
dflp['bins'] = pd.qcut(dflp['Pred1'],10)
dflp.groupby('bins')[['y','Pred1']].sum()

Now the batch way to set the false positive rate, given you have a well calibrated model is as follows. Sort your batch according the predicted probability of the positive class in descending value. Pretend we have a simple set of four cases:
Prob
0.9
0.8
0.5
0.1
Now if we set the threshold to be 0.6, we would then have {0.9,0.8} as our two predictions, we then estimate that the false positive rate would be (0.1 + 0.2)/2 = 0.3/2, If we set the threshold to be 0.4, we would have a false positive rate estimate of (0.1 + 0.2 + 0.5)/3 = 0.8/3. So this relies on a batch of characteristics that we are predicting, and is not determined beforehand (this is the idea I use in this post on prioritizing audits):
# The batch way to set the false positive rate
ptestl = logitm.predict_proba(test[xvar])
dftp = pd.DataFrame(ptestl,columns=['Pred0','Pred1'],index=test.index)
dftp['y'] = test[yvar]
dftp.sort_values(by='Pred1',ascending=False,inplace=True)
dftp['PredictedFP'] = (1 - dftp['Pred1']).cumsum()
dftp['AcutalFP'] = (dftp['y'] == 0).cumsum()
dftp['CumN'] = np.arange(dftp.shape[0]) + 1
dftp['PredRate'] = dftp['PredictedFP']/dftp['CumN']
dftp['ActualRate'] = dftp['AcutalFP']/dftp['CumN']
dftp.iloc[range(1000,7001,1000)]

What happens if we try to estimate where to set the threshold in the training/calibration data though? NOTE: I have a new blog post showing how to construct a more appropriate estimate of the false positive rate ENDNOTE. In practice, we often need to make decisions one at a time, in the parole case it is not like we hold all parolees in the queue for a month to save and batch process them. So lets use our precision in the calibration sample to get a threshold:
# Using precision to set the threshold (based on calibration set)
fp_set = 0.45
pr_data = precision_recall_curve(cal1[yvar], probsl[:,1])
loc = np.arange(pr_data[0].shape[0])[pr_data[0] > fp_set].min()
thresh_fp = pr_data[2][loc]
print(f'Threshold estimate for FP rate at {fp_set}')
print(f'{thresh_fp:,.3f}')
print(f'\nActual FP rate in test set at threshold {thresh_fp:,.3f}')
test_fprate = 1 - test[yvar][ptest[:,1] > thresh_fp].mean()
print(f'{test_fprate:,.3f}') # this is not a very good estimate!
Which gives us very poor out of sample estimates – we set the false positive rate to 45%, but ends up being 55%:
Threshold estimate for FP rate at 0.45
0.333
Actual FP rate in test set at threshold 0.333
0.549
So I am not sure what the takeaway from that is, whether we need to be doing something else to estimate the false positive rate (like an online learning approach that Chohlas-Wood et al. (2021) discuss). A takeaway though from the NIJ competition I have is that false positives tend to be a noisy measure (and FP for fairness between groups just exacerbates the problem), so maybe we just shouldn’t be worried about false positives at all. In many CJ scenarios, we do not get any on-policy feedback on false positives – think the bail case where you have ROR vs held pre-trial, you don’t observe false positives in that scenario in practice.
Conformal sets though, if you want recall for particular classes are the way to go though. You can also do them for subsets of data, e.g. different conformal thresholds for male/female, minority/white. So have an easy way to accomplish a fairness ideal with post processing. And I may do a machine learning approach to help that friend out with the crime mix in places idea as well (Wheeler & Steenbeek, 2021).
References
- Brantingham, P. J. (2016). Crime diversity. Criminology, 54(4), 553-586.
- Chohlas-Wood, A., Coots, M., Zhu, H., Brunskill, E., & Goel, S. (2021). Learning to be fair: A consequentialist approach to equitable decision-making. arXiv preprint arXiv:2109.08792.
- Circo, G. M., & Wheeler, A. P. (2022). An Open Source Replication of a Winning Recidivism Prediction Model. International Journal of Offender Therapy and Comparative Criminology, Online First
- Kuchibhotla, A.K., & Berk, R.A. (2023). Nested conformal prediction sets for classification with applications to probation data. The Annals of Applied Statistics, 17(1), 761-785.
- Lentz, T.S. (2018). Crime diversity: reexamining crime richness across spatial scales. Journal of Contemporary Criminal Justice, 34(3), 312-335.
- Wheeler, A.P., & Steenbeek, W. (2021). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology, 37, 445-480
- Wheeler, A.P., Steenbeek, W., & Andresen, M. A. (2018). Testing for similarity in area‐based spatial patterns: Alternative methods to Andresen’s spatial point pattern test. Transactions in GIS, 22(3), 760-774.