
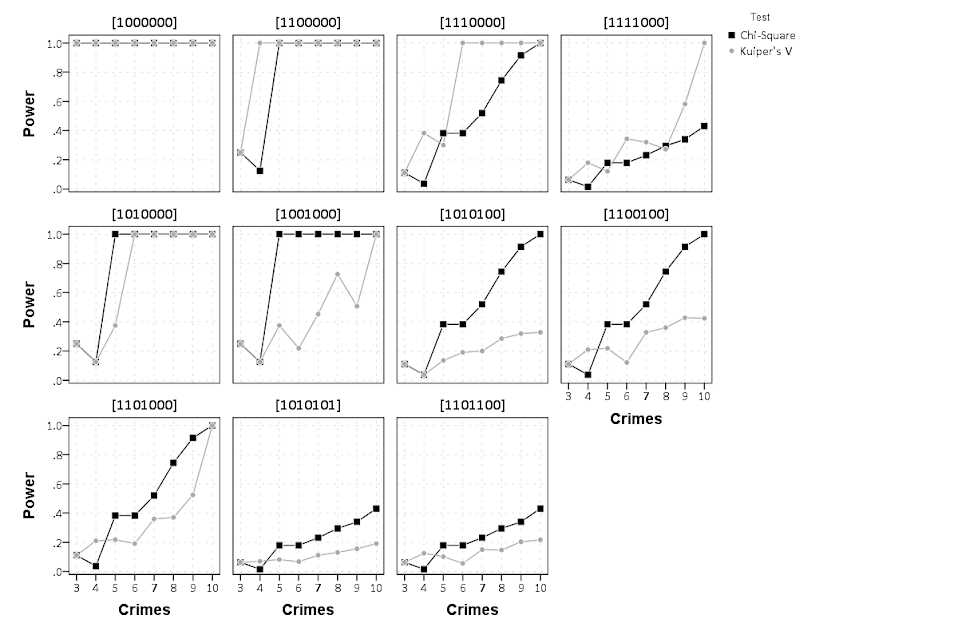
For a project I have been estimating group based trajectory models for counts of crime at micro places. Synonymous with the trajectory models David Weisburd and colleagues estimated for street segments in Seattle. Here I will show how using SPSS and the R package crimCV one can estimate similar group based trajectory models. Here is the crimCV package help and here is a working paper by the authors on the methodology. The package specifically estimates a zero inflated poisson model with the options to make the 0-1 part and/or the count part have quadratic or cubic terms – and of course allows you specify the number of mixture groups to search for.
So first lets make a small set of fake data to work with. I will make 100 observations with 5 time points. The trajectories are three separate groups (with no zero inflation).
*Make Fake data.
SET SEED 10.
INPUT PROGRAM.
LOOP Id = 1 TO 100.
END CASE.
END LOOP.
END FILE.
END INPUT PROGRAM.
DATASET NAME OrigData.
*Make 3 fake trajectory profiles.
VECTOR Count(5,F3.0).
DO REPEAT Count = Count1 TO Count5 /#iter = 1 TO 5.
COMPUTE #i = #iter - 3.
COMPUTE #ii = #i**2.
COMPUTE #iii = #i**3.
DO IF Id <= 30.
COMPUTE #P = 10 + #i*0.3 + #ii*-0.1 + #iii*0.05.
COMPUTE Count = RV.POISSON(#P).
ELSE IF Id <=60.
COMPUTE #P = 5 + #i*-0.8 + #ii*0.3 + #iii*0.05.
COMPUTE Count = RV.POISSON(#P).
ELSE.
COMPUTE #P = 4 + #i*0.8 + #ii*-0.5 + #iii*0.
COMPUTE Count = RV.POISSON(#P).
END IF.
END REPEAT.
FORMATS Id Count1 TO Count5 (F3.0).
EXECUTE.Note The crimCV package wants the data to be wide format for the models, that is each separate time point in its own column. Now we can call R code using BEGIN PROGRAM R to recreate the wide SPSS dataset in an R data frame.
*Recreate SPSS data in R data frame.
BEGIN PROGRAM R.
casedata <- spssdata.GetDataFromSPSS(variables=c("Id","Count1","Count2",
"Count3","Count4","Count5")) #grab data from SPSS
casedataMat <- as.matrix(casedata[,2:6]) #turn into matrix
#summary(casedata) #check contents
#casedataMat[1:10,1:5]
END PROGRAM.Now to fit one model with 3 groups (without calculating the cross validation statistics) the code would be as simple as:
*Example estimating model with 3 groups and no CV.
BEGIN PROGRAM R.
library(crimCV)
crimCV(casedataMat,3,rcv=FALSE,dpolyp=3,dpolyl=3)
END PROGRAM.But when we are estimating these group based trajectory models we don’t know the number of groups in advance. So typically one progressively fits more groups and then uses model selection criteria to pick the mixture solution that best fits the data. Here is a loop I created to successively estimate models with more groups and stuffs the models results in a list. It also makes a separate data frame that saves the model fit statistics, so you can see which solution fits the best (at least based on these statistics). Here I loop through estimates of 1 through 4 groups (this takes about 2 minutes in this example). Be warned – here are some bad programming practices in R (the for loops are defensible, but growing the lists within the loop is not – they are small though in my application and I am lazy).
*looping through models 1 through 4.
BEGIN PROGRAM R.
results <- c() #initializing a set of empty lists to store the seperate models
measures <- data.frame(cbind(groups=c(),llike=c(),AIC=c(),BIC=c(),CVE=c())) #nicer dataframe to check out model
#model selection diagnostics
max <- 4 #this is the number of grouping solutions to check
#looping through models
for (i in 1:max){
model <- crimCV(casedataMat,i,rcv=TRUE,dpolyp=3,dpolyl=3)
results <- c(results, list(model))
measures <- rbind(measures,data.frame(cbind(groups=i,llike=model$llike,
AIC=model$AIC,BIC=model$BIC,CVE=model$cv)))
#save(measures,results,file=paste0("Traj",as.character(i),".RData")) #save result
}
#table of the model results
measures
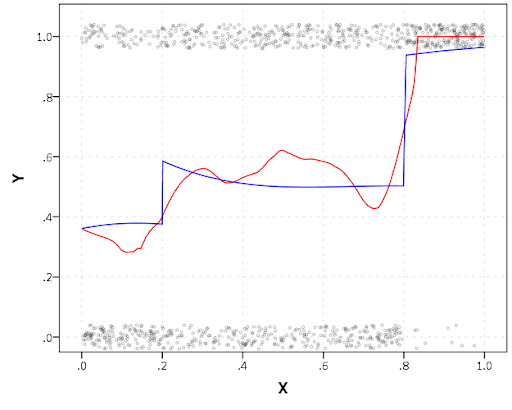
END PROGRAM.In my actual application the groups take a long time to estimate, so I have the commented line saving the resulting list in a file. Also if the model does not converge it breaks the loop. So here we see that the mixture with 3 groups is the best fit according to the CVE error, but the 2 group solution would be chosen by AIC or BIC criteria. Just for this tutorial I will stick with the 3 group solution. We can plot the predicted trajectories right within R by selecting the nested list.
*plot best fitting model.
BEGIN PROGRAM R.
plot(results[[3]])
#getAnywhere(plot.dmZIPt) #this is the underlying code
END PROGRAM.Now the particular object that stores the probabilities is within the gwt attribute, so we can transform this to a data frame, merge in the unique identifier, and then use the STATS GET R command to grab the resulting R data frame back into an SPSS dataset.
*Grab probabiltiies back SPSS dataset.
BEGIN PROGRAM R.
myModel <- results[[3]] #grab model
myDF <- data.frame(myModel$gwt) #probabilites into dataframe
myDF$Id <- casedata$Id #add in Id
END PROGRAM.
*back into SPSS dataset.
STATS GET R FILE=* /GET DATAFRAME=myDF DATASET=TrajProb.Then we can merge this R data frame into SPSS. After that, we can classify the observations into groups based on the maximum posterior probability of belonging to a particular group.
*Merge into original dataset, and the assign groups.
DATASET ACTIVATE OrigData.
MATCH FILES FILE = *
/FILE = 'TrajProb'
/BY ID
/DROP row.names.
DATASET CLOSE TrajProb.
*Assign group based on highest prob.
*If tied last group wins.
VECTOR X = X1 TO X3.
COMPUTE #MaxProb = MAX(X1 TO X3).
LOOP #i = 1 TO 3.
IF X(#i) = #MaxProb Group = #i.
END LOOP.
FORMATS Group (F1.0).Part of the motivation for doing this is not only to replicate some of the work of Weisburd and company, but that it has utility for identifying long term hot spots. Part of what Weisburd (and similarly I am) finding is that crime at small places is pretty stable over long periods of time. So we don’t need to make up to date hotspots to allocate police resources, but are probably better off looking at crime over much longer periods to identify places for targeted strategies. Trajectory models are a great tool to help identify those long term high crime places, same as geographic clustering is a great tool to help identify crime hot spots.













{kind=link}