
Recently came across two different groups broaching the subject of code reviews and reproducible research more broadly for criminal justice. There are certainly aspects of either that make it difficult in the context of peer review. But I am not one to let the perfect be the enemy of the good, so I will layout the difficulties and give some comments on potential good enough solutions that still make marked improvements on the current state of affairs in crim/cj research.
Reproducible Research
So what do I mean by reproducible research? Jeromy Anglim on crossvalidated has a good breakdown on different ways we may apply the term. So to some it may mean if you did a hot spots policing experiment, can I replicate the same crime reduction results in another city.
These are important to publish (simply because social science experiments will inevitably have quite a bit of variance), but this is often not what we are talking about when we talk about replication. We are often talking about a much smaller in scope goal – if I give you the exact same data, can you reproduce the tables/figures in the manuscript you used to make your inferences?
One problem that is often the case with CJ research is that we are working with sensitive data. If I do analysis on a survey of a sensitive topic, I often cannot share the data. But, I do not believe that should entirely put a spike in the question of reproducible data. I have broken down different levels that are possible in making research more reproducible:
- A Sharing data and code files to reproduce the paper results
- B Sharing code files and simulated data that illustrate the results
- C Sharing the plain-text log files showing the code and results of tables/figures
So I have not seen C proposed anywhere, but it is a dead simple solution that almost everyone should be able to accommodate. It simply involves typing log using "output.txt", text at the top of your Stata file, or OUTPUT EXPORT /PDF DOCUMENTFILE="output.pdf" at the end of your SPSS analysis (or could be done via the GUI), etc. These are the log/output files used to generate the results you report in the paper, and typically contain both the commands run, as well as the resulting tables. These files can quite easily not contain privileged information (in fact they won’t be default most of the time, unless you printed out individual names in a table for example in intermediate results).
To accomplish C does take some modicum of wherewithal in terms of writing code, but it is a pretty low bar. So I see no reason why all quantitative analyses cannot require at least this step right now. I realize it is not foolproof – a bad actor could go and edit the results (same as they could edit the results without this information). But it ups the level of effort to manipulate results by quite a bit, and more importantly has the potential to catch more mundane transcription errors that occur quite frequently.
Sometimes I want more details on the code used, the nature of the data etc. (Most quasi-experimental design for example can be summed up as shape your data in a special way and run a particular regression model.) For people like me who care about that, B helps with that, in that I can see the code front-to-back, can actually go and inspect the shape and values in a particular rectangular dataset, and see how the code interacts with those objects. The only full on example of this I am aware of is a recent example paper in Nature Behavior that shares the code using simulated data.
B is also very similar to people who release statistical packages to reproduce their code. So if you release an R package that conducts your new fancy technique, even if you can’t share your data it is really good for people to be able to view the underlying code even by itself to understand the technique better and in conjunction build on your work more. If you do a new technique, it is a crazy ton of work to replicate that on your own, so most people will not bother.
A is most of the way there to the gold standard – if you can share both the data and the code used to reproduce the analysis. Both A and B take a significant amount of knowledge of statistical programming to accomplish. Most people in our field do not have the skills to write an analysis front-to-back that can run in a series of scripts though. To get to A/B grad programs in crim/cj need to spend crazy more time on teaching these skills, which is near zero now almost across the board.
One brief thing to mention about A is that the boundary is difficult to define. So for example, I share code to reproduce analysis in my 311 and crime at micro places in DC paper (paper link, code). But this starts from a dataset that has the street units in DC and all of the covariates already compiled. But where did that dataset come from? I created it by compiling many different sources, so the base dataset is itself very difficult to replicate. Again not letting the perfect be the enemy of the good, I think just starting from your compiled dataset, and replicating the tables/graphs in the manuscript is better than letting the fuzzy boundary prevent you from sharing anything.
Code Reviews for Journal Submissions
The hardest part of A is that even after you share your data, some journals want to be able to run the code locally to entirely reproduce your results. So while I have shared data code (A above) for many papers, see this spreadsheet, they have not been externally vetted by any of those journals. This vetting is the standard in some economic journals now I believe, and would not be surprised in some poli-sci journals as well. This is a very hard problem though, and requires significant resources from both the journal and the researcher to be able to do that.
The biggest hurdle is that even if you share your data/code, your particular system may be idiosyncratic. You may have different R libraries installed than me. You may have different versions of python packages. I may have used a program on Windows to do some analysis you cannot do on a Mac. You may rely on some paid API I cannot access.
These are often solvable problems, but take quite a bit of time to work out. A comparable example to my work is when data scientists say ‘going to production’. This often involves taking some analysis I did on my local machine, and making it run autonomously on my companies servers. There are some things that make it more or less difficult than the typical academic situation, but I think it is broadly comparable. To go to production for a project will typically take me 3-6 months at 50% of my time, so maybe something like 300 hours for a lowish end estimate. And that is just the time it takes from the researchers end, from the journals end it will also take a significant amount of time to compile every ones code and verify the results.
Because of this, I don’t think the fully reproducible re-run my code and generate the exact same tables are feasible in the current way we do academic research and peer review. But again that is why I list C above – we shouldn’t let the perfect be the enemy of the good.
Validating New Empirical Techniques
The code review above is not really code review in the sense that someone looks at your code and says this is correct, it is simply just saying can I get the same results as you. You may want peer review to accomplish the task of not only saying is it reproducible, but is it valid/correct? There are a few things towards this end I would like to see more often in crim/cj. I realize we are not statistics, so cannot often ask for formal proofs. But there are simpler things we can do to verify the results. These are the responsibility of the researcher to provide, not the reviewer to script up on their own to validate someone elses work.
One, illustrate the technique using a very simplified example. So for instance, in my p-median patrol areas paper, I show an example of constructing the linear program with only four areas. You should be able to calculate what the result should be by hand, so can verify the correctness of your algorithm. This has the added benefit of being a very good pedagogical way to describe your method.
Two, illustrate the technique on a larger sample of simulated data in which you again know the correct result. For one example of this, I showed how to estimate group based trajectory models using deep learning libraries. Again your model/method should be able to recover the correct result (which you know) given the simulated fake data.
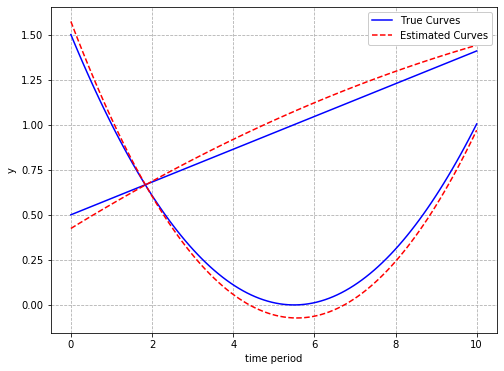
Three, validate the result using real data compared to the current standard. For crime mapping papers, this means comparing forecasts compared to RTM, or simpler regression models, or simply prior crime = future crime on out of sample data. Amazingly many machine learning papers in CJ do not do out of sample predictions. If it is an inferential procedure, comparing the results to some other status quo technique is similar, such as showing conformal prediction intervals have smaller widths (so more statistical power) than placebo results for synthetic control designs (at least for that example with state panel level crime data).
You may not have all three of these examples in any particular paper, but I think for very new techniques 1 or 2 is necessary. 3 is often a by-product on the analysis anyway. So I do not believe any of these asks are that onerous. If you have the skills to create some new technique, you should be able to accomplish 1 or 2.
I do not have any special advice in terms of the reviewers perspective. When I do code reviews at work, what we do is go line by line, and my co-workers give high level design advice. E.g. you should use a config file for this instead of defining it inline, you should turn this block into a function, you should make a class to open/close the database connections etc. The code reviews do not validate the technical correctness, so if I queried the wrong data they wouldn’t know in the code review. The proof is in the pudding so to speak, so if my results are performing really badly in the real world I know I am doing something wrong. (And the obverse, if my results are on the mark and making money I am pretty sure I did nothing terribly wrong.)
Because there are not these real world mechanisms to validate code in peer reviewed papers, my suggestions for 1/2/3 are the closest I think we can get in many circumstances. That and simply making your code available will dramatically improve the reproducibility and validity of your research compared to the current status quo in our field.


1 Comment