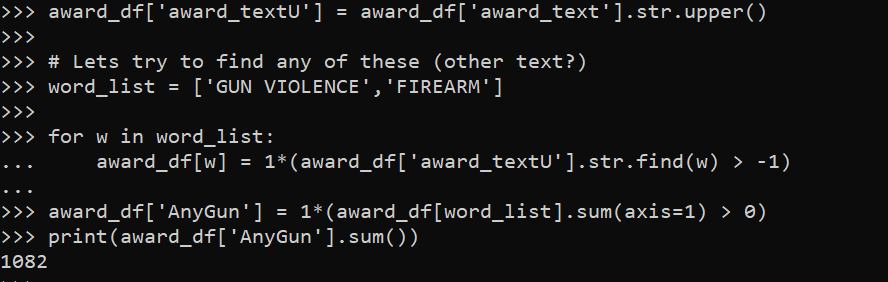
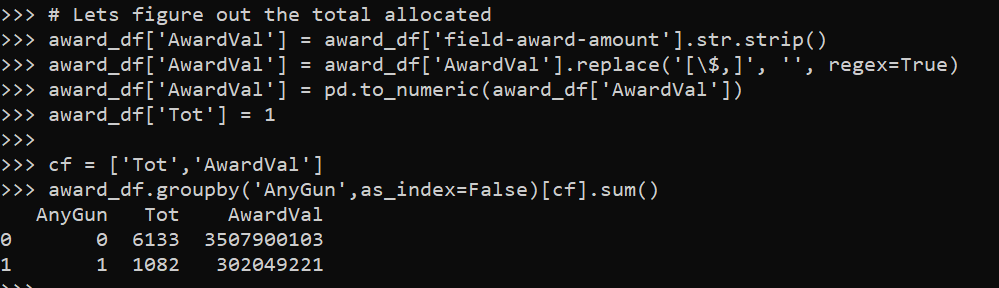
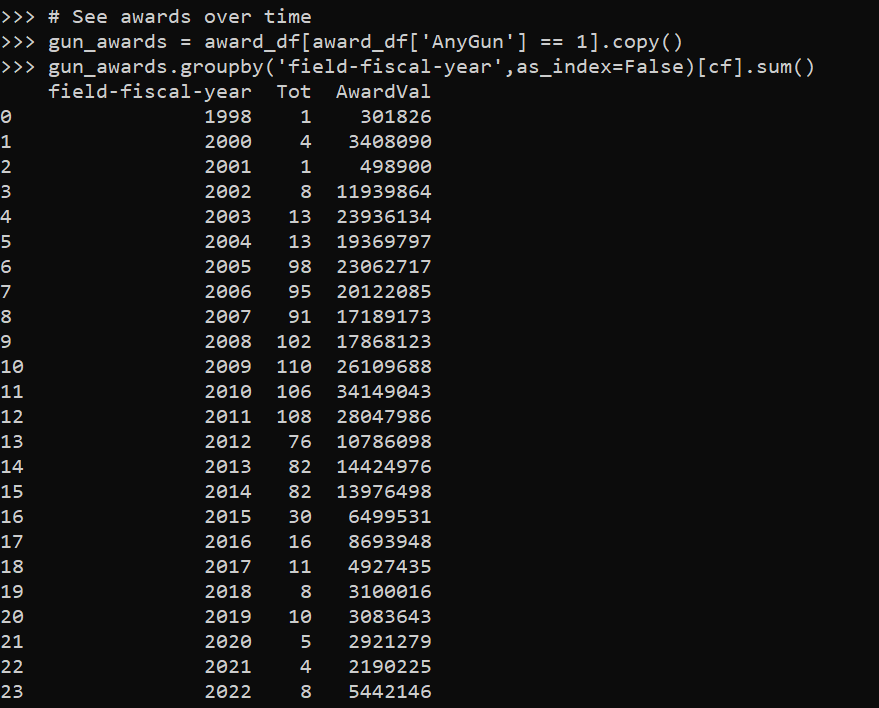
The other day I noticed one of my PhD cohort mates, like me, took a private sector data science job. So of the 6 that finished their Phds in my cohort, 2 of us are now in private sector and the rest are professors. I was curious the overall rate for a larger sample.
There is probably some better official source, but I was able to do a search in Proquest dissertations (SUNY we needed to submit it there), for "State University of New York at Albany" AND "School of Criminal Justice" published between 2010 through 2020 and it scooped up a pretty good sample (with a few false positives I eliminated). I then added in a few people I noticed missing in that set, in the end 69 total over the 11 years (6 defenses per year actually seemed high to me). (Using the WayBack machine you can look at old Phd profiles or the old list of dissertations, but I am not sure of the completeness of either.) Then I filled in their current main job best I could into professor, private sector, university research center, think tank, government (and a few I did not even hazard a guess), based on LinkedIn/google searches/personal knowledge.
Here is the spreadsheet, let me know if you think I miscategorized you or your dissertation is missing altogether. Filtering based on the year of the dissertation is not the same as cohort (you could have started along time ago and more recently defended), but looks to me a pretty reasonable sample of “recent” Phd’s from SUNY Albany Criminal Justice program. Also missing at this Proquest search phase is likely to be missing at random (the few who were not scooped up in my search I see no reason to think are systematic based on Proquest’s idiosyncratic search). But missing in terms of me being able to look once you are in the sample is not (since if you are a professor you probably come up in a general google search for your university).
I tended to be liberal for who I listed as professor (this includes temp teaching jobs and postdocs, but not people who are adjuncts). Many people not in the professor list though were formerly professors (myself included), but tried to figure out the current main job for individuals.
The breakdown for the 69 dissertations is then:
Prof 34 49%
Gov 18 26%
Private 6 9%
Univ Research 3 4%
Think Tank 1 1%
Don't Know 7 10%So private sector is lower overall than in my cohort, only 10% over the time period (and highest possible sample estimate is 19%, if all 7 don’t know are actually in private sector). Government jobs being at 26% I don’t find surprising, think tank and private is lower than I would have guessed though.
But from this I take away around 50% of recent PhDs in criminal justice from SUNY go on to be professors. For prospective PhDs, this estimate is also conditional on completing the PhD (they aren’t in the sample if they did not finish). If you include those individuals Gov/Private would go up in overall proportions.
Again if missing in the list or miscategorized let me know and I will update the post.