I recently did an interview with Manny San Pedro on his YouTube channel, All About Analysis. We discuss various data science projects I conducted while either working as an analyst, or in a researcher/collaborator capacity with different police departments:
Here is an annotated breakdown of the discussion, as well as links to various resources I discuss in the interview. This is not a replacement for listening to the video, but is an easier set of notes to link to more material on what particular item I am discussing.
0:00 – 1:40, Intro
For rundown of my career, went to do PhD in Albany (08-15). During that time period I worked as a crime analyst at Troy, NY, as well as a research analyst for my advisor (Rob Worden) at the Finn Institute. My research focused on quant projects with police departments (predictive modeling and operations research). In 2019 went to the private sector, and now work as an end-to-end data scientist in the healthcare sector working with insurance claims.
You can check out my academic and my data science CV on my about page.
1:40 – 7:30, Outliers in Crime Trends
I discuss the workshop I did at the IACA conference in 2017 on temporal analysis in Excel.
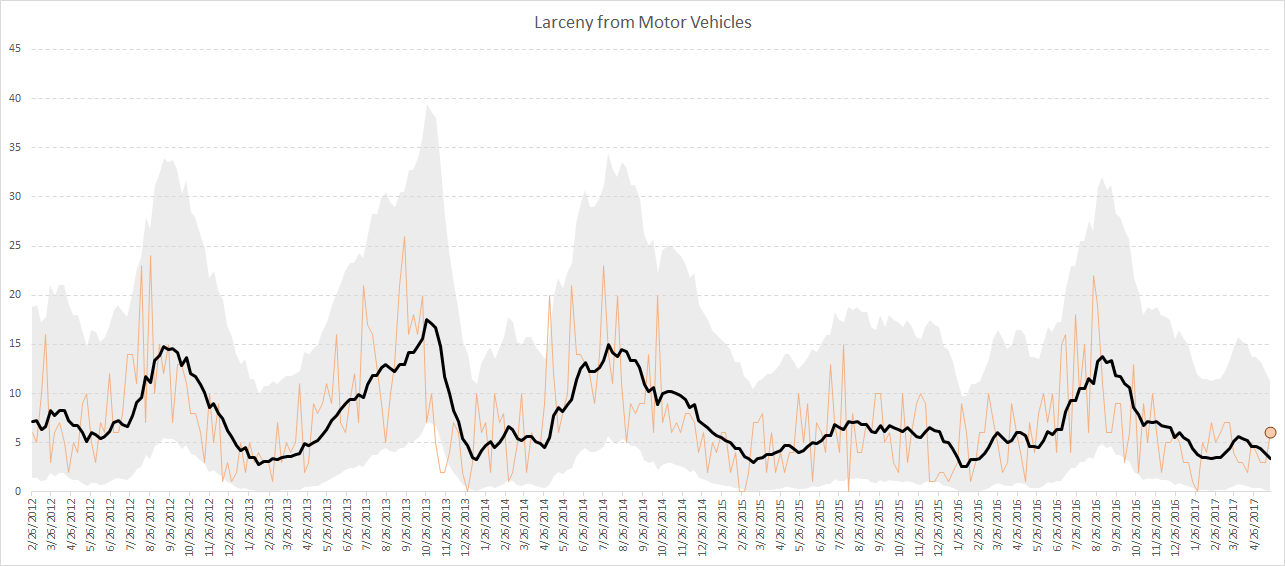
Long story short, don’t use percent change, use other metrics and line graphs.
7:30 – 13:10, Patrol Beat Optimization
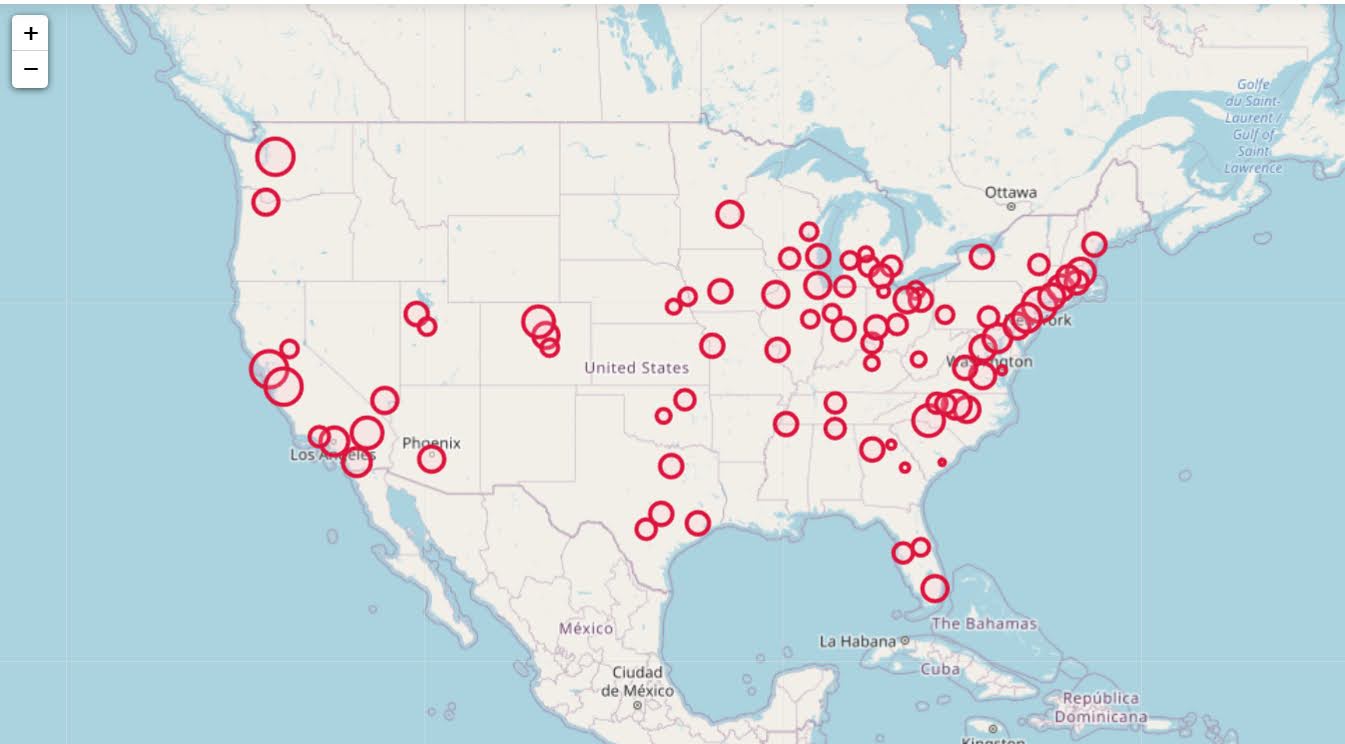
I have the paper and code available to replicate my work with Carrollton PD on patrol beat optimization with workload equality constraints.
For analysts looking to teach themselves linear programming, I suggest Hillier’s book. I also give examples on linear programming on this blog.
It is different than statistical analysis, but I believe has as much applicability to crime analysis as your more typical statistical analysis.
13:10 – 14:15, Million Dollar Hotspots
There are hotspots of crime that are so concentrated, the expected labor cost reduction in having officers assigned full time likely offsets the position. E.g. if you spend a million dollars in labor addressing crime at that location, and having a full time officer reduces crime by 20%, the return on investment for hotspots breaks even with paying the officers salary.
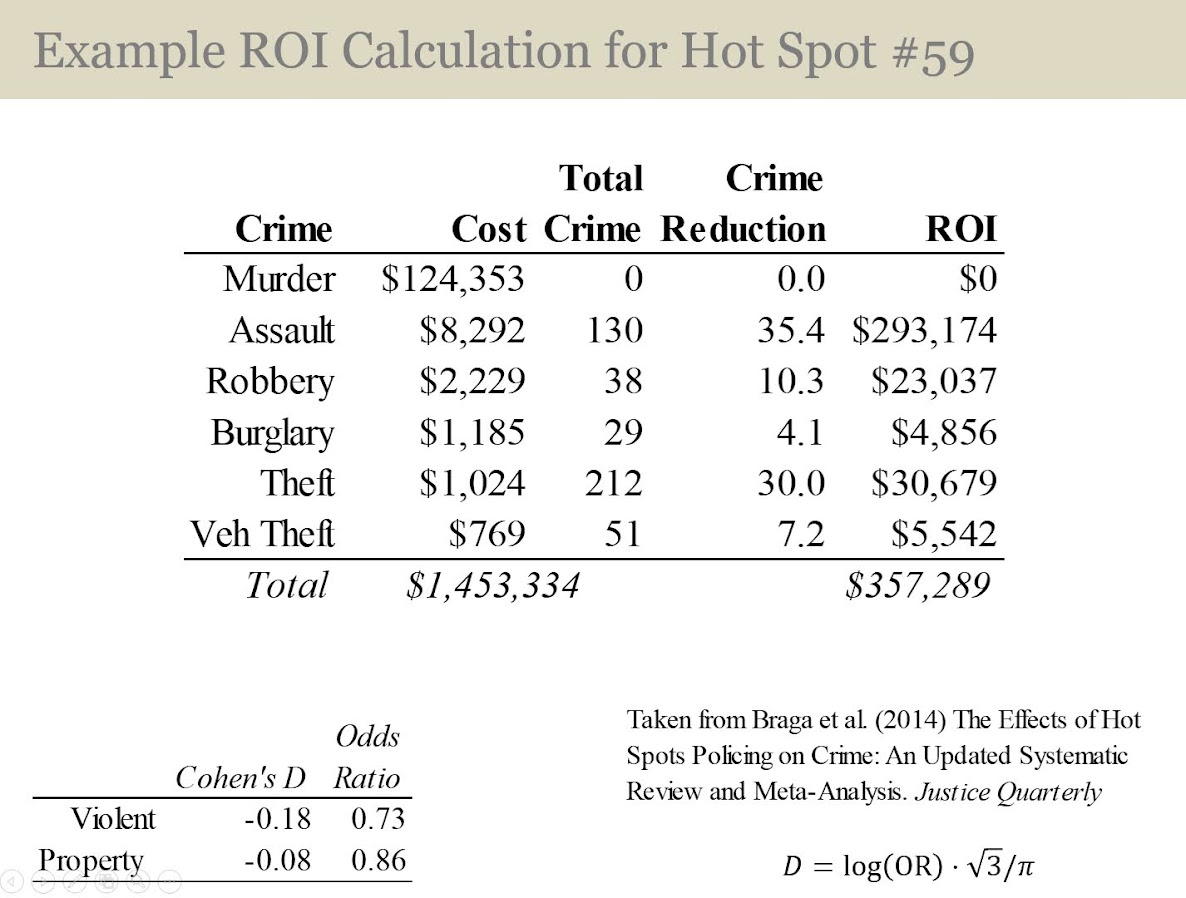
I call these Million dollar hotspots.
14:15 – 28:25, Prioritizing individuals in a group violence intervention
Here I discuss my work on social network algorithms to prioritize individuals to spread the message in a focussed deterrence intervention. This is opposite how many people view “spreading” in a network, I identify something good I want to spread, and seed the network in a way to optimize that spread:
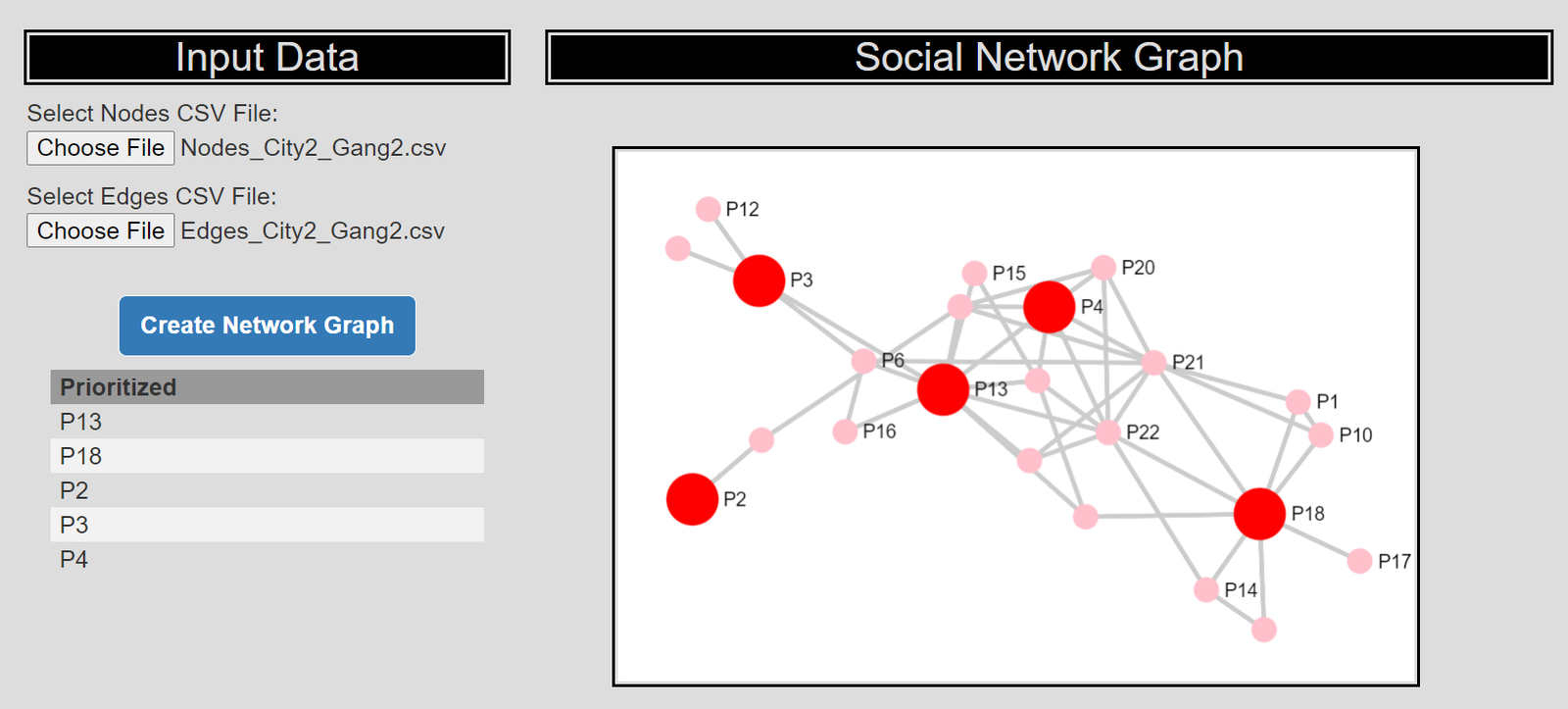
I also have a primer on SNA, which discusses how crime analysts typically define nodes and edges using administrative data.
Listen to the interview as I discuss more general advice – in SNA it matters what you want to accomplish in the end as to how you would define the network. So I discuss how you may want to define edges via victimization to prevent retaliatory violence (I think that would make sense for violence interupptors to be proactive for example).
I also give an example of how detective case allocation may make sense to base on SNA – detectives have background with an individuals network (e.g. have a rapport with a family based on prior cases worked).
28:25 – 33:15, Be proactive as an analyst and learn to code
Here Manny asked the question of how do analysts prevent their role being turned into more administrative role (just get requests and run simple reports). I think the solution to this (not just in crime analysis, but also being an analyst in the private sector) is to be proactive. You shouldn’t wait for someone to ask you for specific information, you need to be defining your own role and conducting analysis on your own.
He also asked about crime analysis being under-used in policing. I think being stronger at computer coding opens up so many opportunities that learning python, R, SQL, is the area I would like to see stronger skills across the industry. And this is a good career investment as it translates to private sector roles.
33:15 – 37:00, How ChatGPT can be used by crime analysts
I discuss how ChatGPT may be used by crime analysis to summarize qualitative incident data and help inform . (Check out this example by Andreas Varotsis for an example.)
To be clear, I think this is possible, but the tech I don’t think is quite up to that standard yet. Also do not submit LEO sensitive data to OpenAI!
Also always feel free to reach out if you want to nerd out on similar crime analysis questions!