It is academics favorite pastime to complain about peer review. There is no getting around it – peer review is degrading, both in the adjective sense of demoralizing, as well as in the verb ‘wear down a rock’ sense.
There is nothing quite like it in other professional spheres that I can tell. For example if I receive a code review at work, it is not adversarial in nature like peer review is. I think most peer reviewers treat the process like a prosecutor, poking at all the minutia that they can uncover, as opposed to being judges of the truth.
At work I also have a pretty unobjectional criteria for success – if my machine learning model is making money then it is good. Not so for academic papers. Despite everyone learning about the ‘scientific method’, academics don’t really have a coda to follow like that. And that lack of objective criteria causes quite a bit of friction in the peer review process.
But all the things I think are wrong with peer review I have a hard time articulating succinctly. So we have a bias problem, in that reviewers have preferences for particular methods or styles. We have a problem that individuals get judged based on highly arbitrary standards of what is interesting. Many critiques are focused on highly pedantic things that make little to no material difference, such as the use of personal pronouns. Style advice can be quite bad to be frank, in my career I’m up to something like four different peer reviews saying providing results in the introduction is inappropriate. Edit: And these complaints are not exhaustive as well, we have reviewers pile on endless complaints in multiple rounds, and people phone it in with nonsense short descriptions as well. (I’m sure I can continue to add to the list, but I’ve personally experienced all of these things, in addition to being called a racist in peer review.)
I’ve previously provided advice about how I think peer reviews should be done. To sum up my advice:
- Differentiate between big problems and minor stuff
- Be very specific what things you want changed (and how to change them)
I think I should add two to this as well – don’t be a jerk, and don’t pile on (or be respectful of peoples time). For the jerk part I don’t even meet that standard if I am being honest with myself. For one of my peer reviews I am going to share a later round I got pretty snippy (with the Urban folks on their CCTV paper in Milwaukee), that was over the top in retrospect. (I don’t think reviewers should get a say on revisions, editors should just arbiter whether the responses by the original authors were sufficient. I am pretty much never happy if I suggest something and an author says no thanks.)
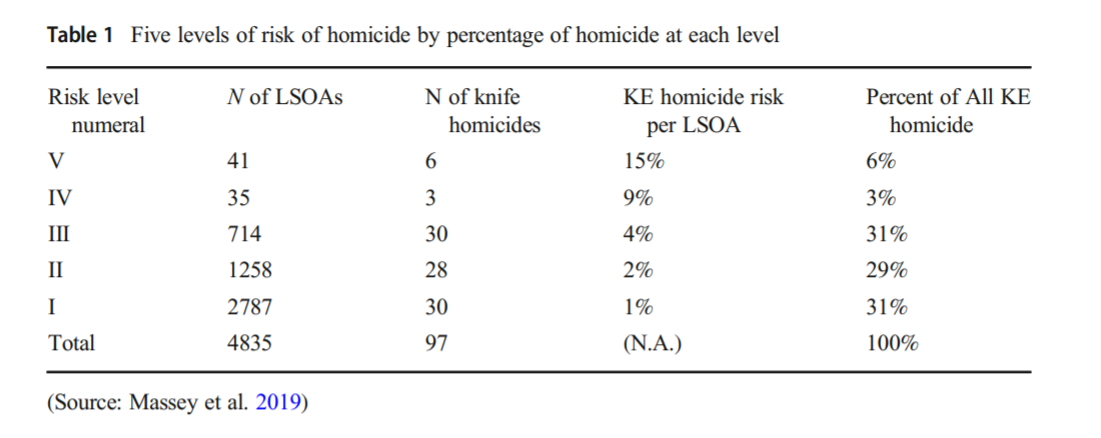
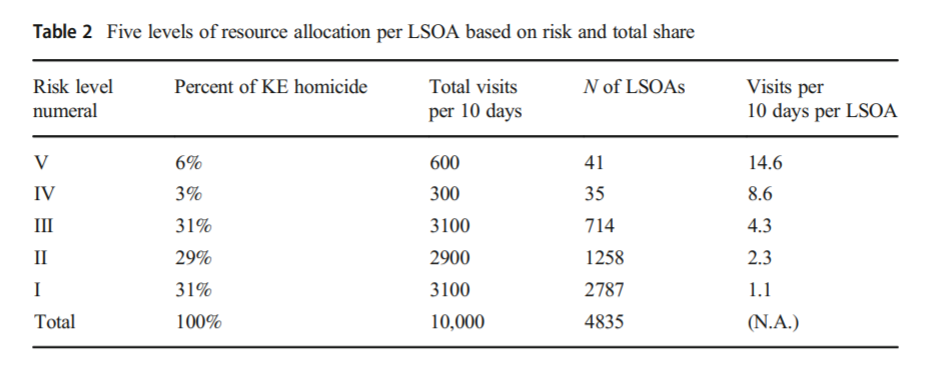
For the pile on part, I recently posted my responses to my cost of crime hot spots paper. Although all three reviewers were positive, it still took me ~40 hours to respond to all of the critiques. Even though all of the reviews were in good faith, it honestly was not worth my time to make those revisions. (I think two were legitimate, changing the front end to say my hot spots are crime cost, not crime harm, and the ask for more details on the Hunt estimates. The rest were just fluff though.)
If you do consulting think about your rate – and whether addressing all those minor critiques meet the threshold of ‘is the paper improved by the amount to justify my consulting fee’. My experience it does not come close, and I am quite a cheap consultant.
So I have shared in the past a few examples of my response to reviewers (besides above, see here for the responses to my how to select participants for focussed deterrence paper, and here for my tables and graphs for crime analysis paper). But maybe instead of bagging on others, I should just try to lead by example.
So below are several of my recent reviews. I’ve only pulled out the recent ones that I know the paper has been published. This is then subject to a selection bias, papers I have more negative things to say are less likely to be published in the end. So keep that bias in mind when judging these.
The major components of how I believe I am different from the modal reviewer is I subdivide between major and minor concerns. Many reviewers take the running commentary through the paper approach, which not only does not distinguish between major/minor, but many critiques are often explicitly addressed (just at a different point in the manuscript from where it popped into the reviewers head).
The way I do my reviews I actually do the running commentary in the side of the paper, then I sleep on it, then I organize into the major sections. In this process of organizing I drop quite a bit of minor fluff, or things that are cleared up at later points in the paper. (I probably end up deleting ~50% of my original notes.)
Second, for papers I give a thumbs up for I take actual time to articulate why they are good. I don’t just give a complement sandwich and pile on a series of minor critiques. Positive comments are fleeting in peer review, but necessary to judge a piece.
So here are some of my examples from peer review, take them for what they are worth. I no doubt do not always follow my advice I lay out above, by try my best to.
Title: Going Local: Do Consent Decrees and Other Forms of Federal Intervention in Municipal Police Departments Reduce Police Killings?
The article is well written and a timely topic. The authors have a quote that I think sums it up quite nicely “This paper is therefore the first to evaluate the effects of civil rights investigations and the consent decree process on an important – arguably the most important – measure of use of force: death.” Well put.
The analysis is also well executed. It is observational, but city fixed effects and the event history study were the main things I was looking for.
I have a three major revision requests. But they are just editing the manuscript type stuff, so can be easily accomplished by the authors.
- Drop the analysis of Crime Rates
While I think the analysis of officer deaths is well done, the analysis of crime rates I have more doubts about. Front end is not focused on this at all, and would need a whole different section about it discussing recent work in Chicago/Baltimore/NYC. Also I don’t think the same analysis (fixed effects), is sufficient for crime trends – we are basically talking about the crime drop period. Also very important to assess heterogeneity in that analysis – a big part of the discussion is that Chicago/Baltimore are different than NYC.
The analysis of officer deaths is sufficient to stand on its own. I agree the crime rates question is important – save it for another paper where it can be given enough attention to do the topic justice.
- Conclusion
Like I said, I was most concerned about the event study, and the authors show that there was some evidence of pre-treatment selection trends. You don’t talk about the event study results in the conclusion though. It is a limitation that the event study analysis had less clear evidence of crime reductions than the simpler pre/post analysis.
This is likely due to larger error bars with the rare outcome, which is itself a limitation of using shootings as the outcome. I think it deserves to be mentioned even if overall the effects of consent decrees are not 100% clear on reducing officer involved deaths, locally monitoring more frequent outcomes is worthwhile. See the recent work by MacDonald/Braga in NYC. New Orleans is another example, https://journals.sagepub.com/doi/full/10.1177/1098611117709785.
I note the results are important to publish without respect to the results of the analysis. It would be important to publish this work even if it did not show reductions in officer involved deaths.
- Front end lit review
For 2.2 racial disparities, this section misses much of the recent work on the topic of officer involved shootings except for Greg Ridgeway’s article. There is a wide array of work that uses other counterfactual approaches to examine implicit bias, see Roland Fryer work (https://www.journals.uchicago.edu/doi/abs/10.1086/701423), or the Wheeler/Worrall papers on Dallas shoot/don’t shoot data (https://journals.sagepub.com/doi/full/10.1177/1525107118759900 & https://journals.sagepub.com/doi/full/10.1177/0011128718756038). These are the observational duel to the experimental lab work by Lois James. Also there are separate papers by Justin Nix (https://www.tandfonline.com/doi/full/10.1080/0735648X.2018.1547269), and Joseph Cesario (https://journals.sagepub.com/doi/10.1177/1948550618775108) that show when using different benchmarks estimates of disparity can vary by quite abit.
For the use of force review (section 2.3), people typically talk about situational factors that influence use of force (in addition to individual/extra-legal and organizational). So you may say “consent decrees don’t/can’t change situational behavior of offenders, so what is the point of writing about it” tis true, but it still should be articulated. To the extent that situational factors are a large determinant of shootings, it may be consent decrees are not the right way to reduce officer deaths then if it is all situational. But, consent decrees may indirectly effect police/citizen interactions (such as via de-escalation or procedural justice training), that could be a mechanism through which fewer officer deaths occur.
Long story short, 2.2 should be updated with more recent work on officer involved shootings and the benchmark problem, and 2.3 should be updated to include discussion of the importance of situational factors in the use of force.
Additional minor stuff:
- pg 12, killings are not a proxy for use of force (they count as force!)
- regression equations need some editing. Definitely need a log or exponential function on one of the sides of the equation, and generalized linear models do not have an error term like linear models do. I personally write them as:
log(E[crime_it]) = intercept + B1*X + …..
where E[crime_it] is the expected value of crime at place i and time t (equivalent to lambda in your current formulation).
- pg 19 monitor misspelled (equation type)
Title: Immigration Enforcement, Crime and Demography: Evidence from the Legal Arizona Workers Act
Well done paper, uses current status quo empirical techniques to estimate the effect employment oversight for illegal immigrant workers had on subsequent crime reductions.
Every critique I thought of was systematically addresses in the paper already. Discussed issues with potential demographic spillovers (biasing estimates because controls may have crime increases). Eliminating states from the pool of placebos with stronger E-Verify support, and later on robustness checks for neighboring states. And using some simple analyses to give decompositions that would be expected due to the decrease in the share of young males.
Minor stuff
- Light and Miller quote on pg 21 not sure if it is space/dash missing or just kerning problems in LaTex
- Pg 26, you do the estimates for 08 and 09 separately, but I think you should pool 08-09 together in that table (the graphs do the visual tests for 08 & 09 independently). For example, Violent crimes are negative for both 08 & 09, which in the graphs are not outside the typical bounds for each individual year, but cumulatively that may be quite low (most will have a variable low and then high). This should get you more power I think given the few potential placebo tests. So it should be something like (-0.067 + -0.108) with error bars for violent crimes.
- I had to stare at your change equation (pg 31) for quite a bit. I get the denominator of equation 2, I’m confused about the numerator (although it is correct). Here is how I did it (using your m1, m2, a, and X).
Pre-Crime = m1*aX + (1 - m1)X = X * (m1*a + 1 - m1)
Post-Crime = m2*aX + (1 - m2)X = X * (m2*a + 1 - m2) #so you can drop the X
% Change = (Post - Pre) / Pre = Post/Pre - 1
At least that is easier for me to wrap my head around. Also should m1 and m2 be the overall share of young adults? Not just limited to immigrants? (Since the estimated crime reduction is for everybody, not just crimes committed by immigrants?)
Title: How do close-circuit television cameras impact crimes and clearances? An evaluation of the Milwaukee Police Department’s public surveillance system
Well written paper. Uses appropriate quasi-experimental methods (matching and diff-in-diff) to evaluate reductions in crimes and potential increases in case clearances.
I have some minor requests on analysis/descriptive stats, but things that can be easily addressed by the authors.
First, I would request a simpler pre-post DiD table. The panel models not only introduce more complications of interpretation, but they are based on asymptotics that I’m not sure if they are met here.
So if you do something like:
Pre Crime Post Crime Difference DiD
Treated 100 80 -20 -30
Control 100 110 10
It is much more straightforward to interpret, and I provide a stat test and power analysis advice in https://crimesciencejournal.biomedcentral.com/articles/10.1186/s40163-018-0085-5. Your violent crime counts are very low, so I think you would need unrealistic effects (of say 50% reductions) to detect an effect with your group sizes.
You can do the same table for % clearances, and do whatever binomial test of proportions (which will have much more power than the regression equation). And again is simpler to interpret.
Technically doing a poisson regression with an exposure is not the same as modelling the clearance counts with total crimes as an exposure. The predicted PMF can technically go above 1 (so you can have %’s above 100%). It would be more appropriate to use binomial regression, so something like below in Stata:
glm arrests i.Treat i.Post Treat#Post i.Unit, family(binomial crimes) link(logit)
(No xtbinomial unfortunately, maybe can coerce xtlogit with weights to do it, or use meglm since you are doing random effects. I think you should probably do fixed effects here anyway.) I don’t know if it will make a difference in the results here though.
Andy Wheeler
Title: The formation of suspicion: A vignette study
Well done experimental study examining suspiciousness using a vignette approach. There is no power analysis done, but it is a pretty large sample, and only examines first order effects. (With a note about examining a well powered interaction effect described in the analysis section.)
My only big ask is that the analysis should include a dummy variable for the two different sampling frames (e.g. a dummy variable for 1=New York). Everything else is minor/easy stuff.
Minor stuff:
- How were the vignettes randomized? (They obviously were, balance is really good!)
- For the discussion, it is important to understand these characteristics that start an interaction because of another KT heuristic bias – anchoring effects. Paul Taylor has some recent work of interest on Dispatch priming that is relevent. (Also Dan Mears had a recent overview paper on biases/heuristics in Journal of Criminal Justice I also think should probably be cited.)
- For Table 1 I would label the “Dependent Variable” with a more descriptive label (suspiciousness)
- Also people typically code the variables 0/1 instead of 1/2, it actually won’t impact the analysis here, since it is just a linear shift of +1 (just change the intercept term). The variables of Agency Size, Education, & Experience are coded as ordinal variables though, and they should maybe be included as dummy variables for each category. (I don’t think this will make a big difference though for the main randomized variables of interest though.)
Title: The criminogenic effect of marijuana dispensaries in Denver, Colorado: A microsynthetic controls quasi-experiment and cost-benefit analysis
This work is excellent. It is a timely topic, as many states are still considering whether to legalize and what that will exactly look like.
The work is a replication/extension of a prior study also in Denver, but this is a stronger research design. Using the micro units allows for matching on pre-trends and drawing synthetic controls, which is a stronger design than prior pre/post work at neighborhood level (both in Denver and in LA). Micro units are also more relevant to test direct criminogenic effects of the stores. The authors may be interested in https://www.tandfonline.com/doi/full/10.1080/0735648X.2019.1582351, which is also a stronger research design using matched comparison groups, but is only for medical dispensaries in DC and is a much smaller sample.
Even if one considers that to be a minor contribution (crime increase findings are similar magnitude to Hughes JQ paper), the cost benefit analysis is a really important contribution. It hits on all of the important considerations – that even if the book of costs/benefits is balanced, they are relevant to really different segments of society. So even if tax revenue offsets the books, places may still not want to take on that extra crime burden.
Only two (very minor) suggestions. One, some of the permutation lines are outside of the figure boundaries. Two, I would like a brief ado in the discussion mentioning the trade-off in economic investment making places busier (which fits right into the current discussion of how costs-benefits). Likely if you added 100 ice-cream shops crime might go up due to increased commercial activity – weed has the same potential negative externality – but is not necessarily worse than say opening a bunch of bars or convenience stores. (Same thing is relevant for any BID, https://journals.sagepub.com/doi/full/10.1177/0011128719834559.)
Title: Understanding the Predictors of Street Robbery Hot Spots: A Matched Pairs Analysis and Systematic Social Observation
Note: Reviewed for Justice Quarterly and rejected. Final published version is at Crime & Delinquency (which I was not a reviewer for)
The article uses the case-control method to match high-crime to low-crime street segments, and then examine local land use factors (bars, convenience stores, etc.) as well as the more novel source of physical disorder coded from Google Street View images. The latter is the main motivation for the case-control design, as manual coding prevents one from doing the entire city.
Case-control designs by their nature you cannot manipulate the number of cases you have at your disposal. Thus the majority of such designs typically focus on ONE exposure of interest, and match on any other characteristic that is known to affect the outcome, but is not of direct interest to the study. E.g. if you examined lung cancer given exposure to vehicle emissions, you would need to match controls as to whether they smoked or not. This allows you to assess the exposure of interest with the maximum power given the design limitations, although you can’t say anything about smoking vs not smoking on the outcome.
The authors here match within neighborhoods and on several other local characteristics, but then go onto examine different crime generators (7 factors), as well as the two disorder coded variables. Given that this is a fairly small sample size of 129 matched cases, this is likely a pretty underpowered research design. Logistic regression relies on asymptotic properties, and even with fewer variables it is questionable whether 260 cases is sufficient, see https://www.tandfonline.com/doi/abs/10.1080/02664763.2017.1282441. Thus you get in abstract terms fairly large odds ratios, but are still not significant (e.g. physical disorder has an odds ratio of 1.7, but is insignificant). So you have low power to test all of those coefficients.
I believe a stronger research design would focus on the novel measures (the Google Street View disorder), and match on the crime generator variables. The crime generator factors have been well established in prior research, so that work is a small contribution. The front end focuses on the typical crime generator typology, and lacks any broader “so what” about the disorder measures. (Which can be made, focusing on broken windows theory and the controversy it has caused.)
It would be feasible for authors to match on the crime generators, but it would result in different control cases, so they would need to code additional locations. (If you do match on crime generators, I think it is OK to include 0 crime areas in the pool. Main reason it is sometimes not fair to include 0 crime areas is because they are things like a bridge or a park.)
Minor notes:
- You cannot interpret the coefficients in causal terms on which you matched in the conclusion. (Top page 23.) It only says the extent to which your matching was successful, not anything about causality. Later on you also attempt to weasel out of causal interpretations (page 26). Saying this is not causality, but otherwise interpreting regression coefficients as if they have any meaning is an act of cognitive dissonance.
- Given that there is perfect separation between convenience stores and hot spots, the model should have infinite standard errors for that factor. (You have a few coefficients that appear to have explosive standard errors.)
- I wouldn’t describe as you match on the dependent variable [bottom page 8]. I realize it is confusing mixing propensity score terminology with case-control (although the method is fine). You match cases-to-controls on the independent variables you choose at the onset.
- page 5, Dan O’Brien in his work has shown that you have super-callers for 311. Which fits right into your point of how coding of images may be better, as a single person can bias the measure at micro places. (This is sort of the opposite of not calling problem you mention.)
- You may be interested, some folks have tried to automate the scoring part using computer vision, see https://ieeexplore.ieee.org/document/6910072?tp=&arnumber=6910072&url=http:%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D6910072 or https://mikebader.net/projects/canvas-usa/ . George Mohler had a talk at ASC where he used Google’s automated image labeling to identify disorder (like graffiti) in pictures https://cloud.google.com/vision/docs/labels